8 Cluster Analysis
8.1 Definition
Cluster analysis is the process of grouping objects (variables or observations) into groups based on measures of similarity.
Similar objects are placed in the same cluster, and dissimilar objects are placed in different clusters.
Cluster analysis methods are typically described by algorithms (rather than models or formulas).
8.2 Types of Clustering
Clustering can be categorized in various ways:
- Hard vs. soft
- Top-down vs bottom-up
- Partitioning vs. hierarchical agglomerative
8.3 Top-Down vs Bottom-Up
We will discuss two of the major clustering methods – hierarchical clustering and K-means clustering.
Hierarchical clustering is an example of bottom-up clustering in that the process begings with each object being its own cluster and then objects are joined in a hierarchical manner into larger and larger clusters.
\(K\)-means clustering is an example of top-down clustering in that the number of clusters is chosen beforehand and then object are assigned to one of the \(K\) clusters.
8.4 Challenges
- Cluster analysis method
- Distance measure
- Number of clusters
- Convergence issues
8.5 Illustrative Data Sets
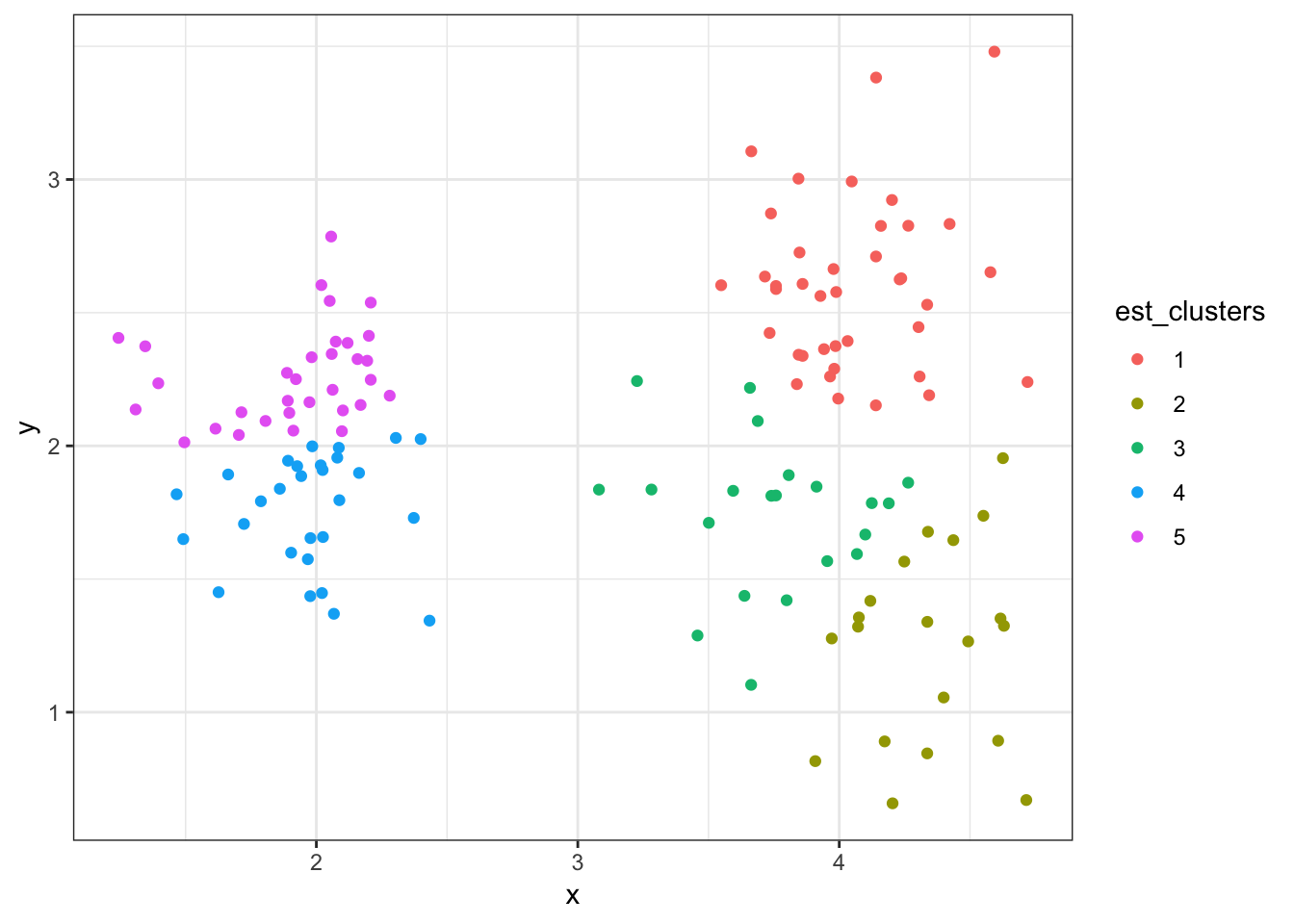
8.5.1 Simulated data1
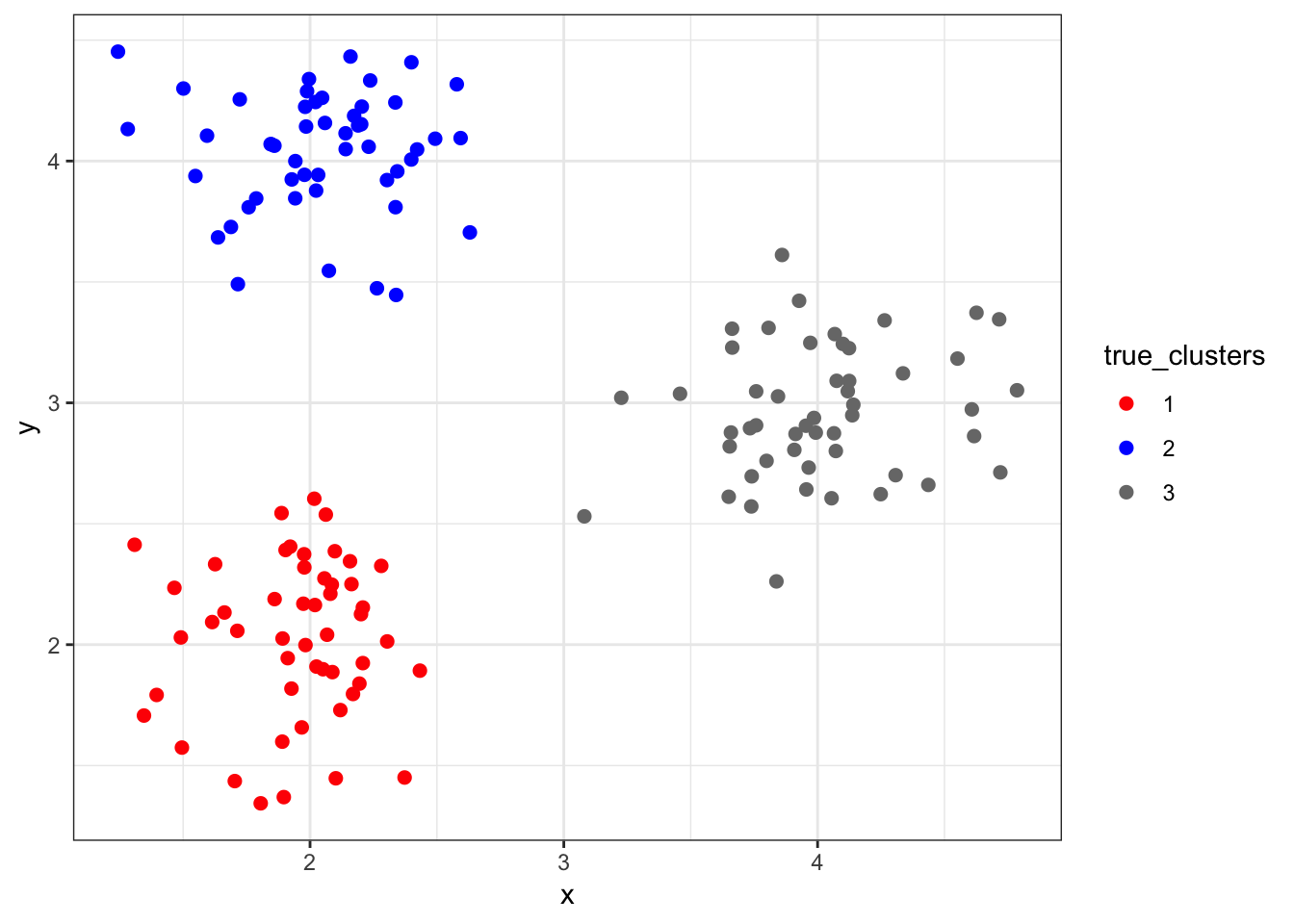
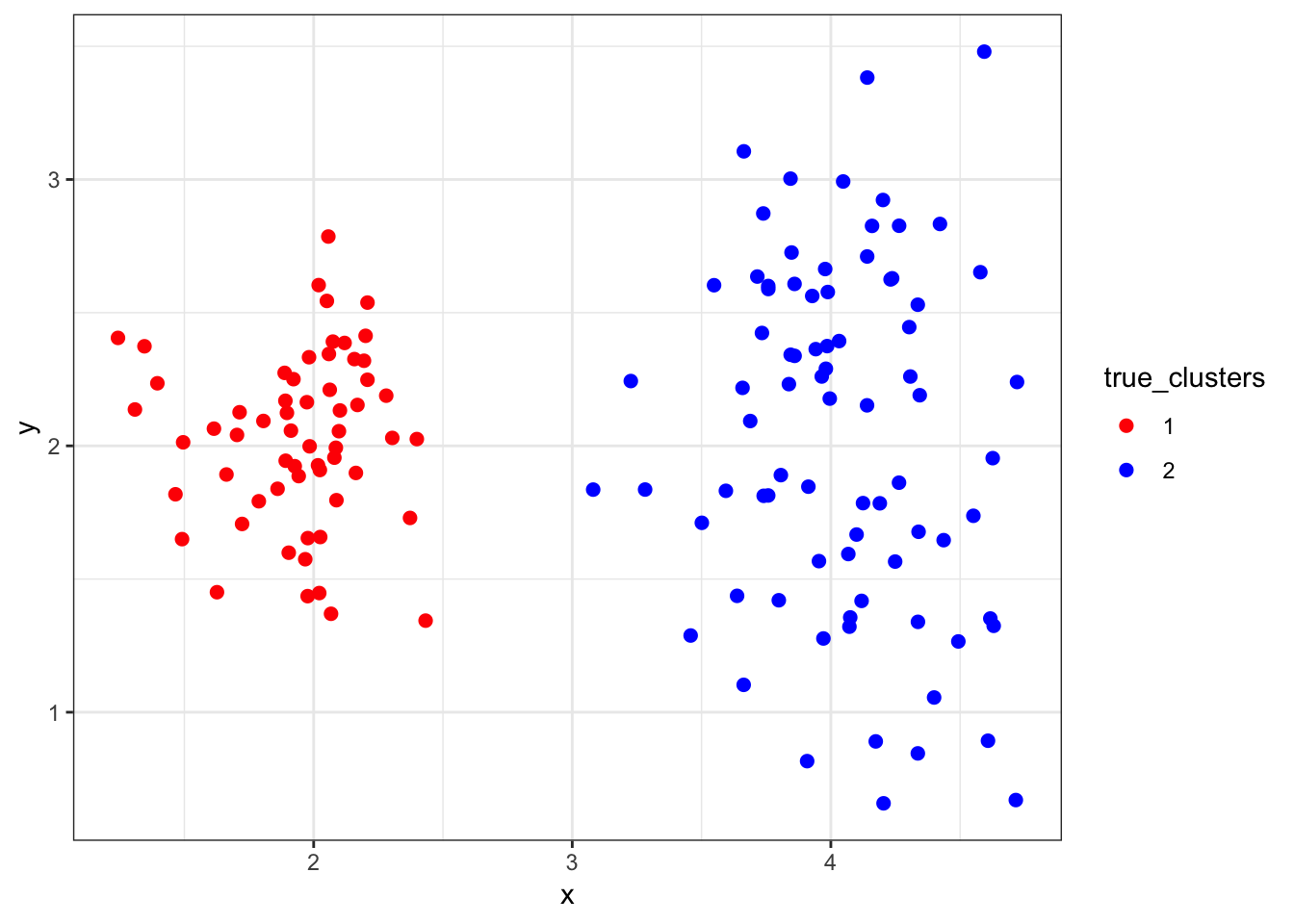
8.5.2 “True” Clusters data1
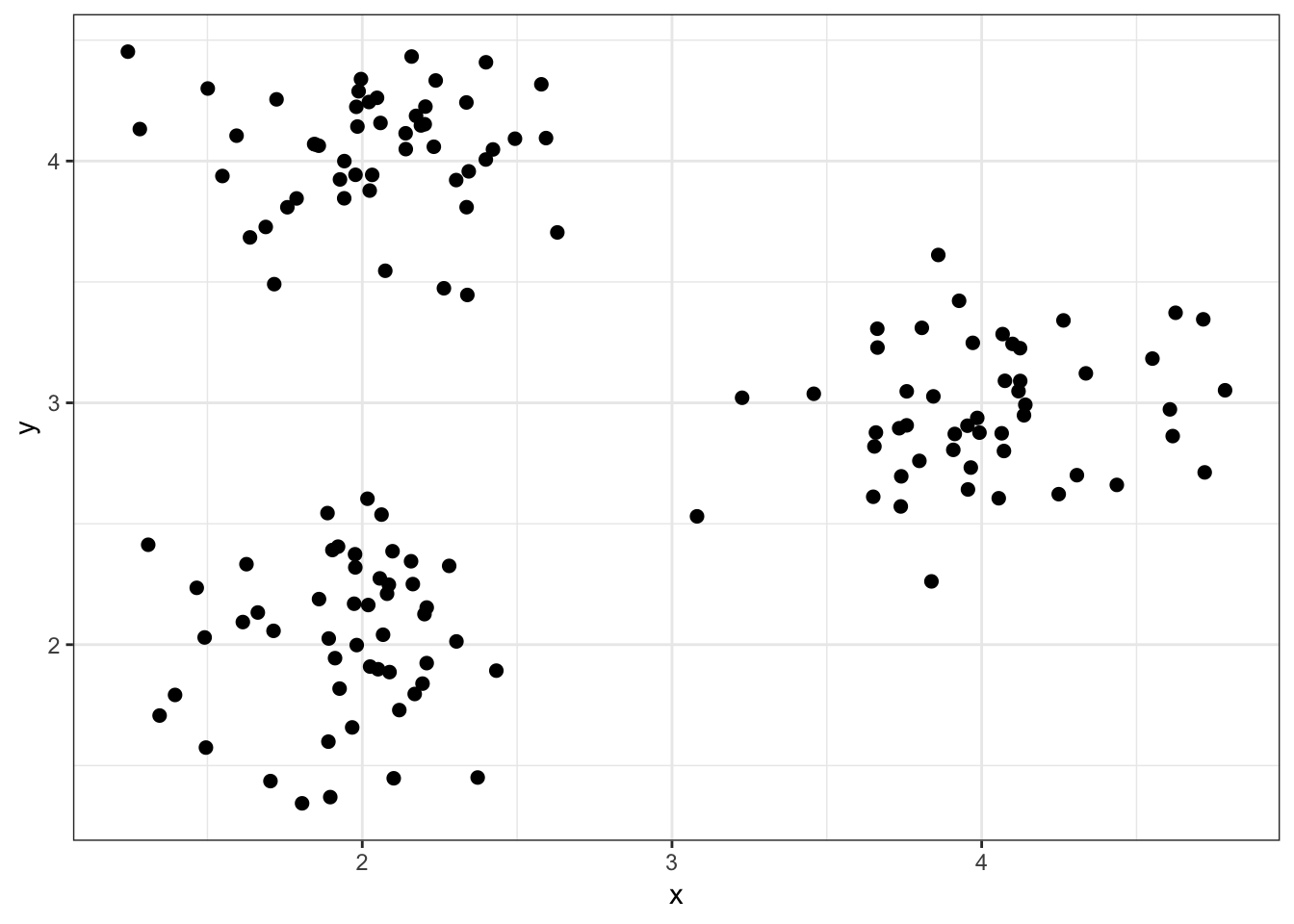
8.5.3 Simulated data2
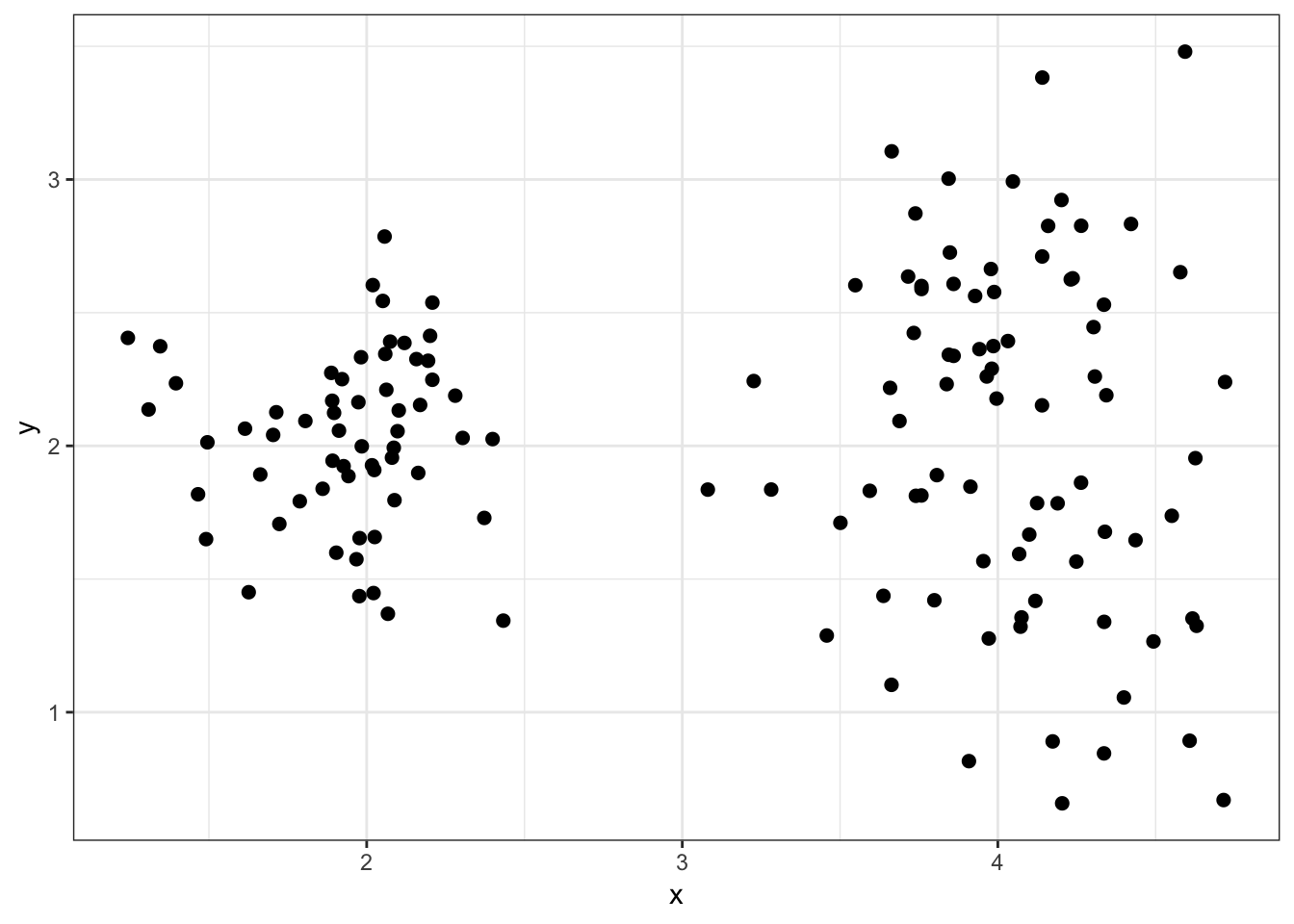
8.5.4 “True” Clusters data2
8.6 Distance Measures
8.6.1 Objects
Most clustering methods require calculating a “distance” between two objects.
Let \(\pmb{a} = (a_1, a_2, \ldots, a_n)\) be one object and \(\pmb{b} = (b_1, b_2, \ldots, b_n)\) be another object.
We will assume both objects are composed of real numbers.
8.6.2 Euclidean
Euclidean distance is the shortest spatial distance between two objects in Euclidean space.
Euclidean distance is calculated as:
\[d(\pmb{a}, \pmb{b}) = \sqrt{\sum_{i=1}^n \left(a_i - b_i \right)^2}\]
8.6.3 Manhattan
Manhattan distance is sometimes called taxicab distance. If you picture two locations in a city, it is the distance a taxicab must travel to get from one location to the other.
Manhattan distance is calculated as:
\[d(\pmb{a}, \pmb{b}) = \sum_{i=1}^n \left| a_i - b_i \right|\]
8.6.4 Euclidean vs Manhattan
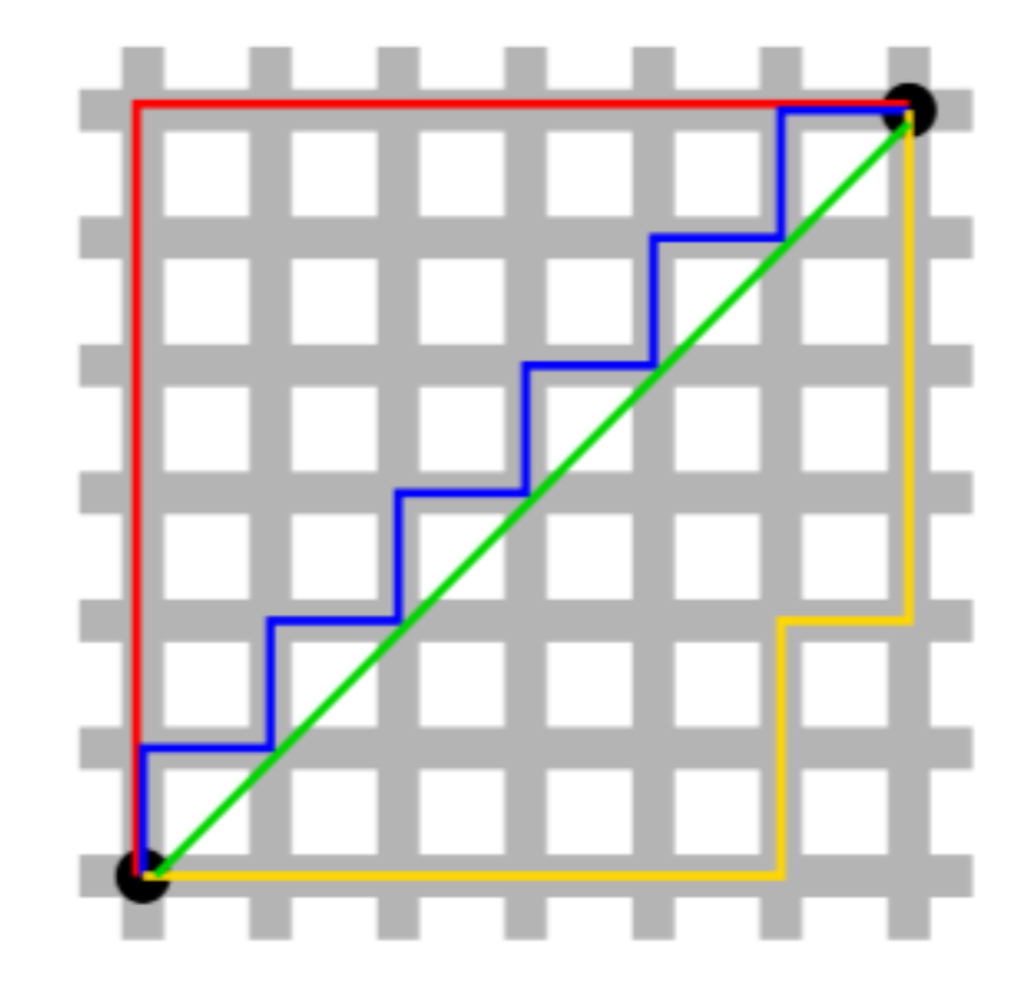
Green is Euclidean. All others are Manhattan (and equal). Figure from Exploratory Data Analysis with R.
8.6.5 dist()
A distance matrix – which is the set of values resulting from a distance measure applied to all pairs of objects – can be obtained through the function dist().
Default arguments for dist():
> str(dist)
function (x, method = "euclidean", diag = FALSE, upper = FALSE, p = 2) The key argument for us is method= which can take values method="euclidean" and method="manhattan" among others. See ?dist.
8.6.6 Distance Matrix data1
> sub_data1 <- data1[1:4, c(1,2)]
> sub_data1
x y
1 2.085818 2.248086
2 1.896636 1.369547
3 2.097729 2.386383
4 1.491026 2.029814
> mydist <- dist(sub_data1)
> print(mydist)
1 2 3
2 0.8986772
3 0.1388086 1.0365293
4 0.6335776 0.7749019 0.7037257> (sub_data1[1,] - sub_data1[2,])^2 %>% sum() %>% sqrt()
[1] 0.89867728.7 Hierarchical Clustering
8.7.1 Strategy
Hierarchical clustering is a hierarchical agglomerative, bottom-up clustering method that strategically joins objects into larger and larger clusters, until all objects are contained in a single cluster.
Hierarchical clustering results are typically displayed as a dendrogram.
The number of clusters does not necessarily need to be known or chosen by the analyst.
8.7.3 Algorithm
The algorithm for hierarchical clustering works as follows.
- Start with each object assigned as its own cluster.
- Calculate a distance between all pairs of clusters.
- Join the two clusters with the smallest distance.
- Repeat steps 2–3 until there is only one cluster.
At the very first iteration of the algorithm, all we need is some distance function (e.g., Euclidean or Manhattan) to determine the two objects that are closest. But once clusters with more than one object are present, how do we calculate the distance between two clusters? This is where a key choice called the linkage method or criterion is needed.
8.7.4 Linkage Criteria
Suppose there are two clusters \(A\) and \(B\) and we have a distance function \(d(\pmb{a}, \pmb{b})\) for all objects \(\pmb{a} \in A\) and \(\pmb{b} \in B\). Here are three ways (among many) to calculate a distance between clusters \(A\) and \(B\):
\[\begin{eqnarray} \mbox{Complete: } & \max \{d(\pmb{a}, \pmb{b}): \pmb{a} \in A, \pmb{b} \in B\} \\ \mbox{Single: } & \min \{d(\pmb{a}, \pmb{b}): \pmb{a} \in A, \pmb{b} \in B\} \\ \mbox{Average: } & \frac{1}{|A| |B|} \sum_{\pmb{a} \in A} \sum_{\pmb{b} \in B} d(\pmb{a}, \pmb{b}) \end{eqnarray}\]8.7.5 hclust()
The hclust() function produces an R object that contains all of the information needed to create a complete hierarchical clustering.
Default arguments for hclust():
> str(hclust)
function (d, method = "complete", members = NULL) The primary input for hclust() is the d argument, which is a distance matrix (usually obtained from dist()). The method argument takes the linkage method, which includes method="complete", method="single", method="average", etc. See ?hclust.
8.7.6 Hierarchical Clustering of data1
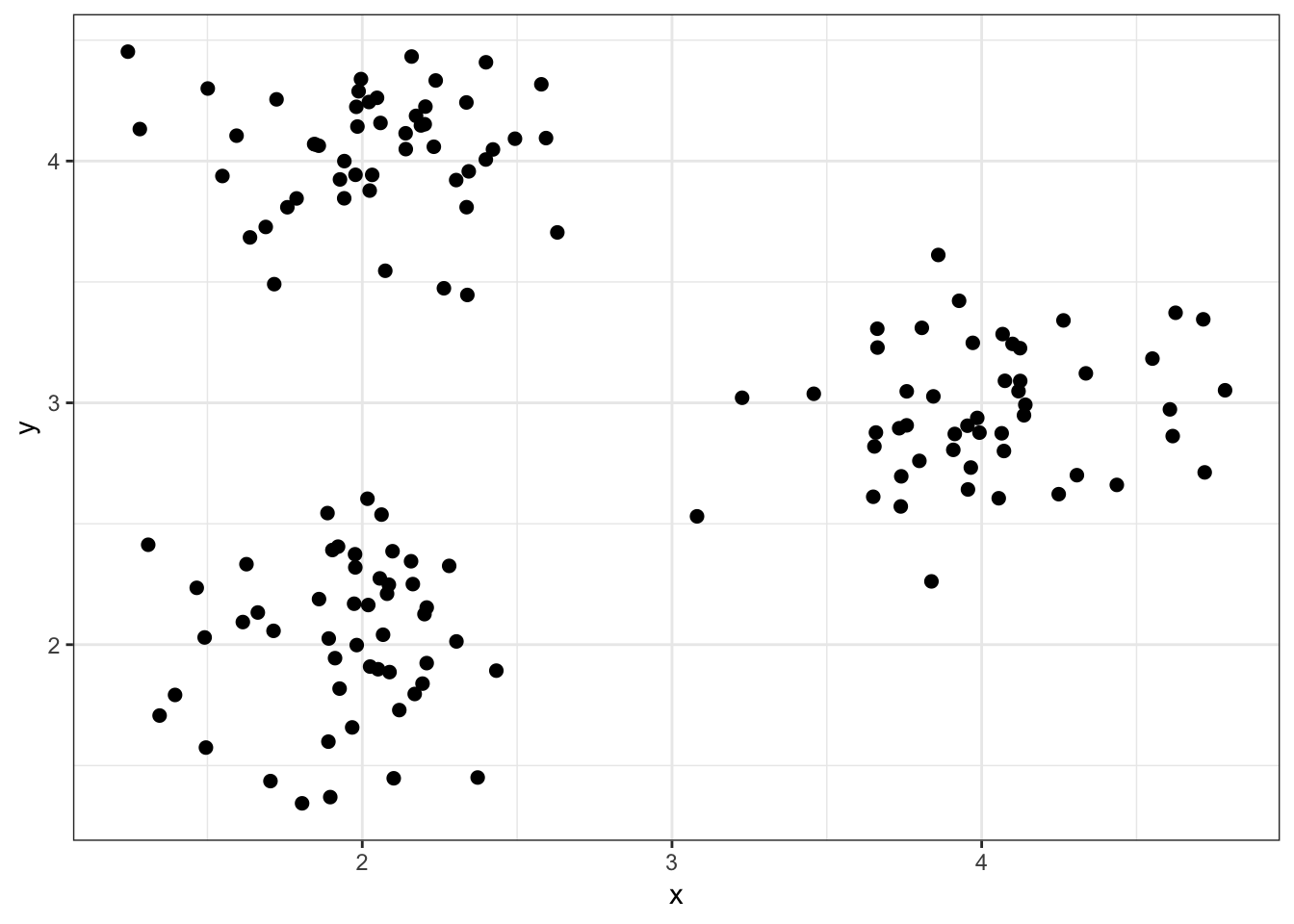
8.7.7 Standard hclust() Usage
> mydist <- dist(data1, method = "euclidean")
> myhclust <- hclust(mydist, method="complete")
> plot(myhclust)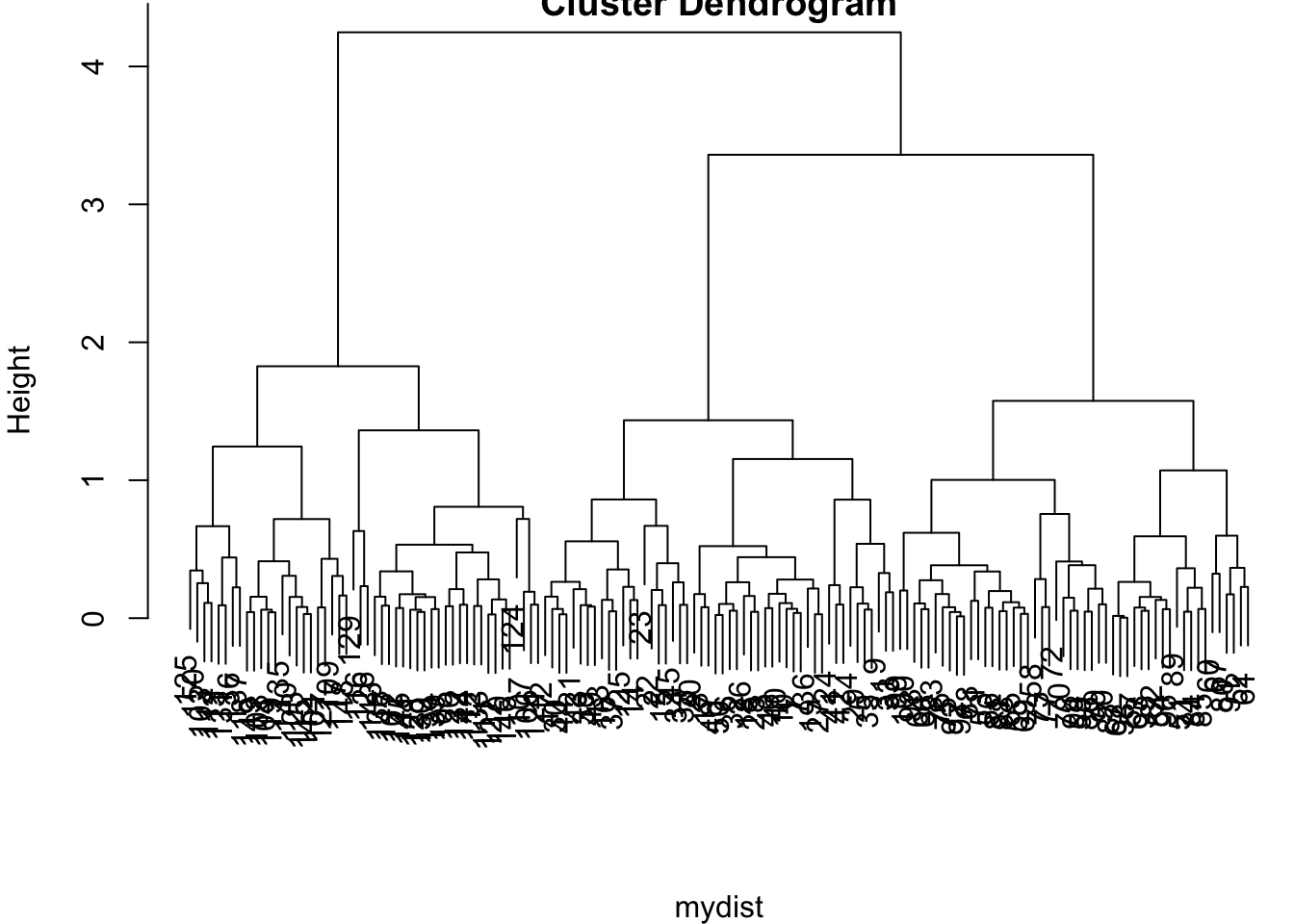
8.7.8 as.dendrogram()
> plot(as.dendrogram(myhclust))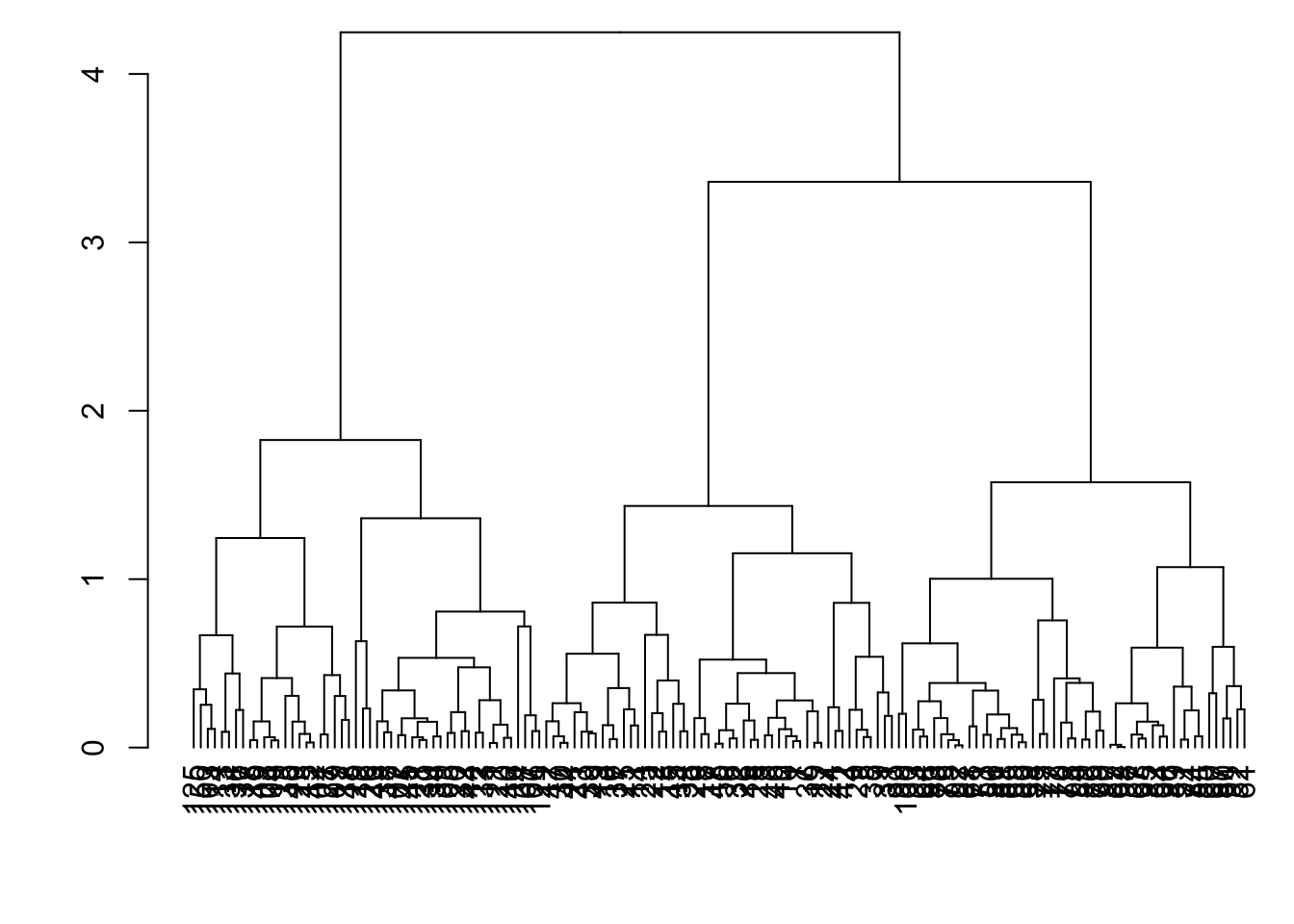
8.7.9 Modify the Labels
> library(dendextend)
> dend1 <- as.dendrogram(myhclust)
> labels(dend1) <- data1$true_clusters
> labels_colors(dend1) <-
+ c("red", "blue", "gray47")[as.numeric(data1$true_clusters)]
> plot(dend1, axes=FALSE, main=" ", xlab=" ")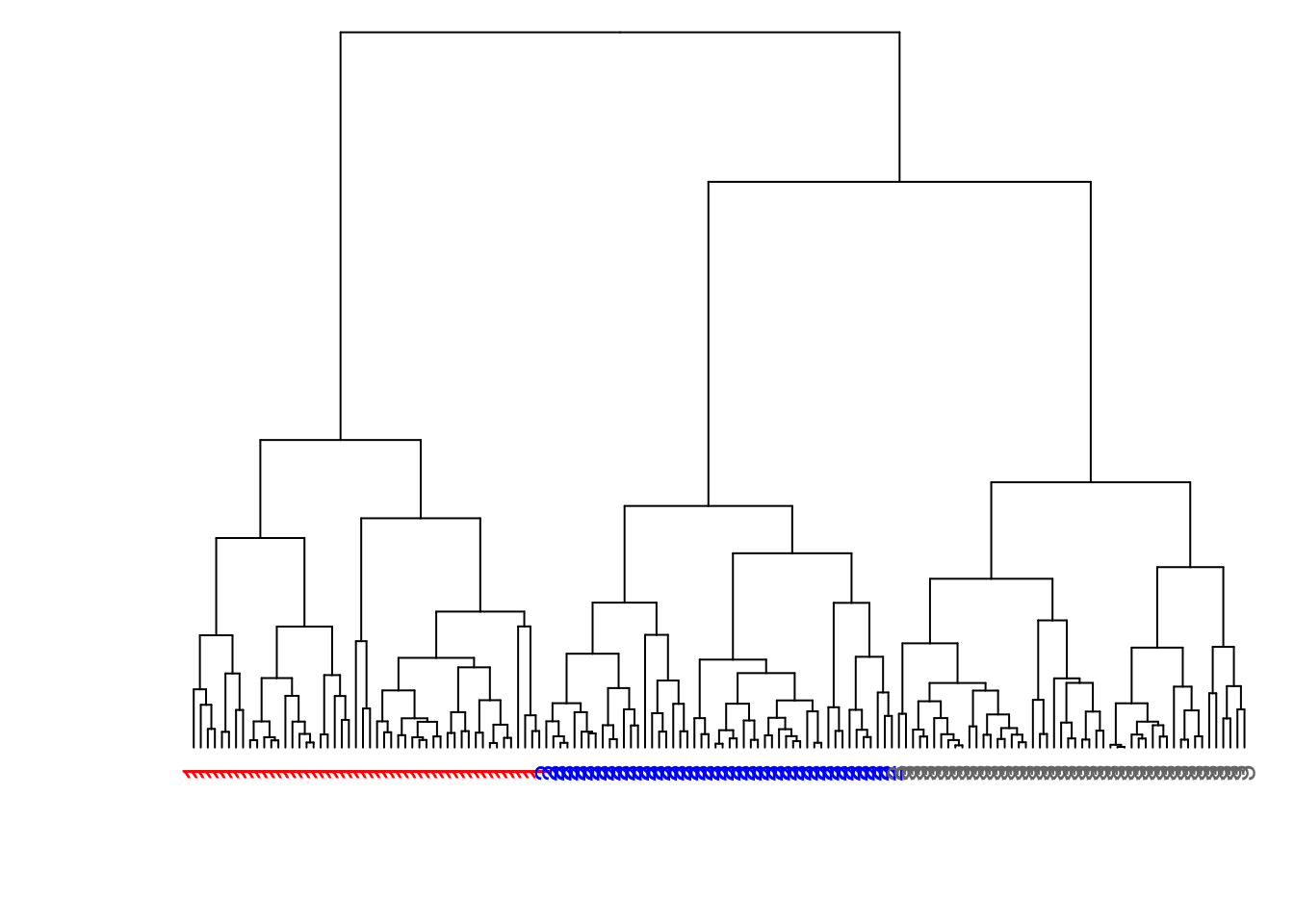
8.7.10 Color the Branches
> dend2 <- as.dendrogram(myhclust)
> labels(dend2) <- rep(" ", nrow(data1))
> dend2 <- color_branches(dend2, k = 3, col=c("red", "blue", "gray47"))
> plot(dend2, axes=FALSE, main=" ", xlab=" ")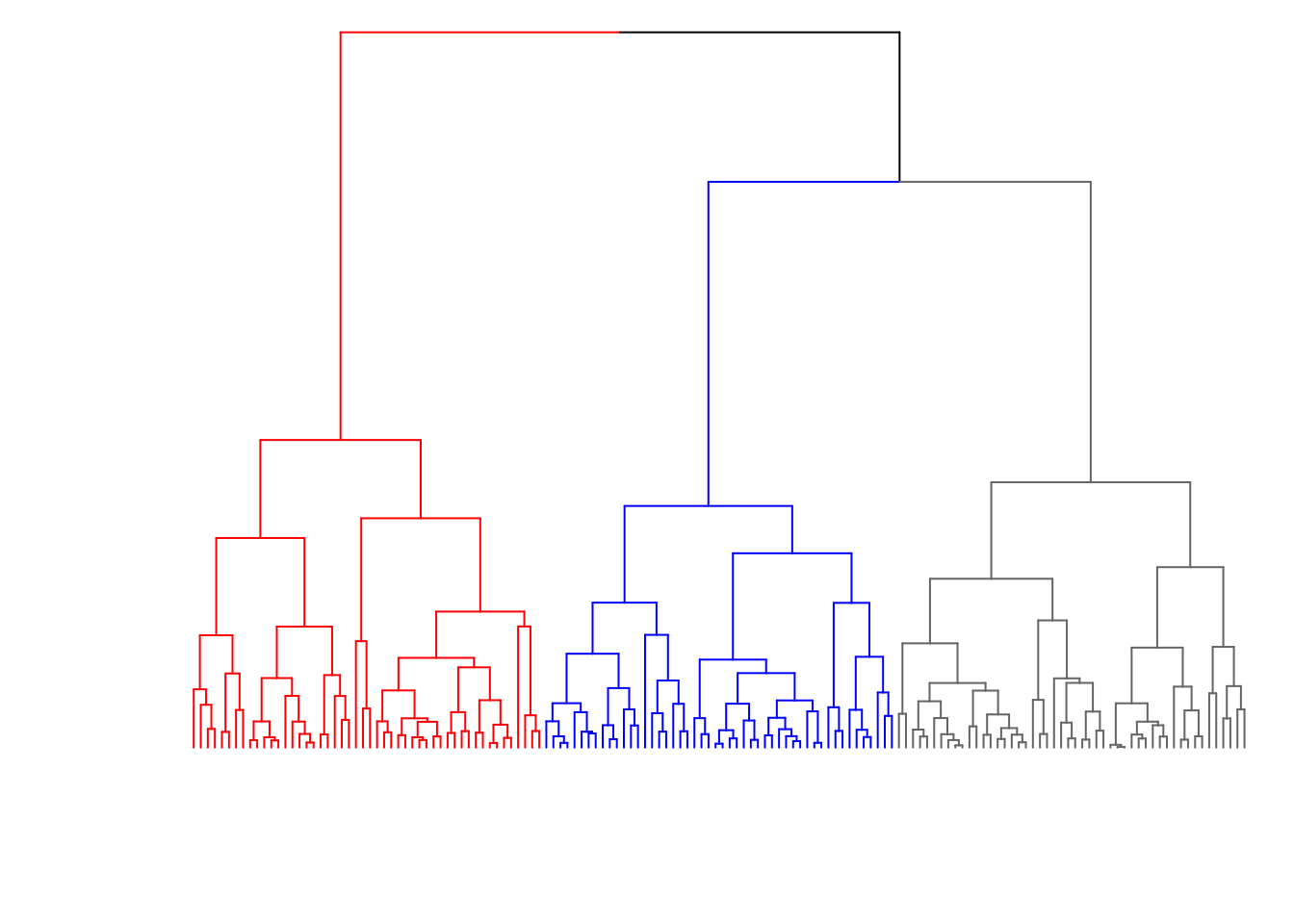
8.7.11 Cluster Assignments (\(K = 3\))
> est_clusters <- cutree(myhclust, k=3)
> est_clusters
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[71] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3
[106] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[141] 3 3 3 3 3 3 3 3 3 3> est_clusters <- factor(est_clusters)
> p <- data1 %>%
+ mutate(est_clusters=est_clusters) %>%
+ ggplot()
> p + geom_point(aes(x=x, y=y, color=est_clusters))8.7.12 Cluster Assignments (\(K = 3\))
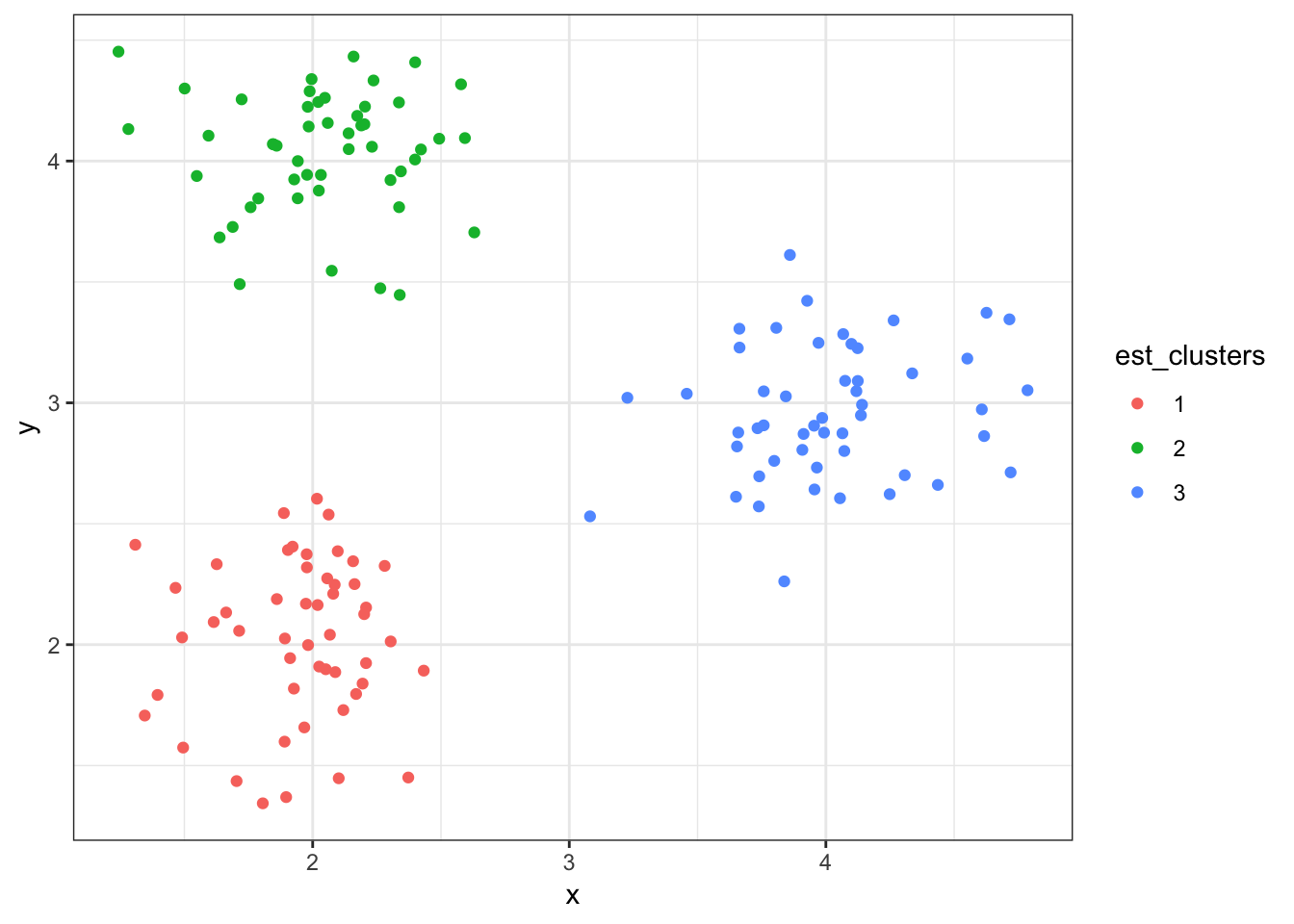
8.7.13 Cluster Assignments (\(K = 2\))
> (data1 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=2))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))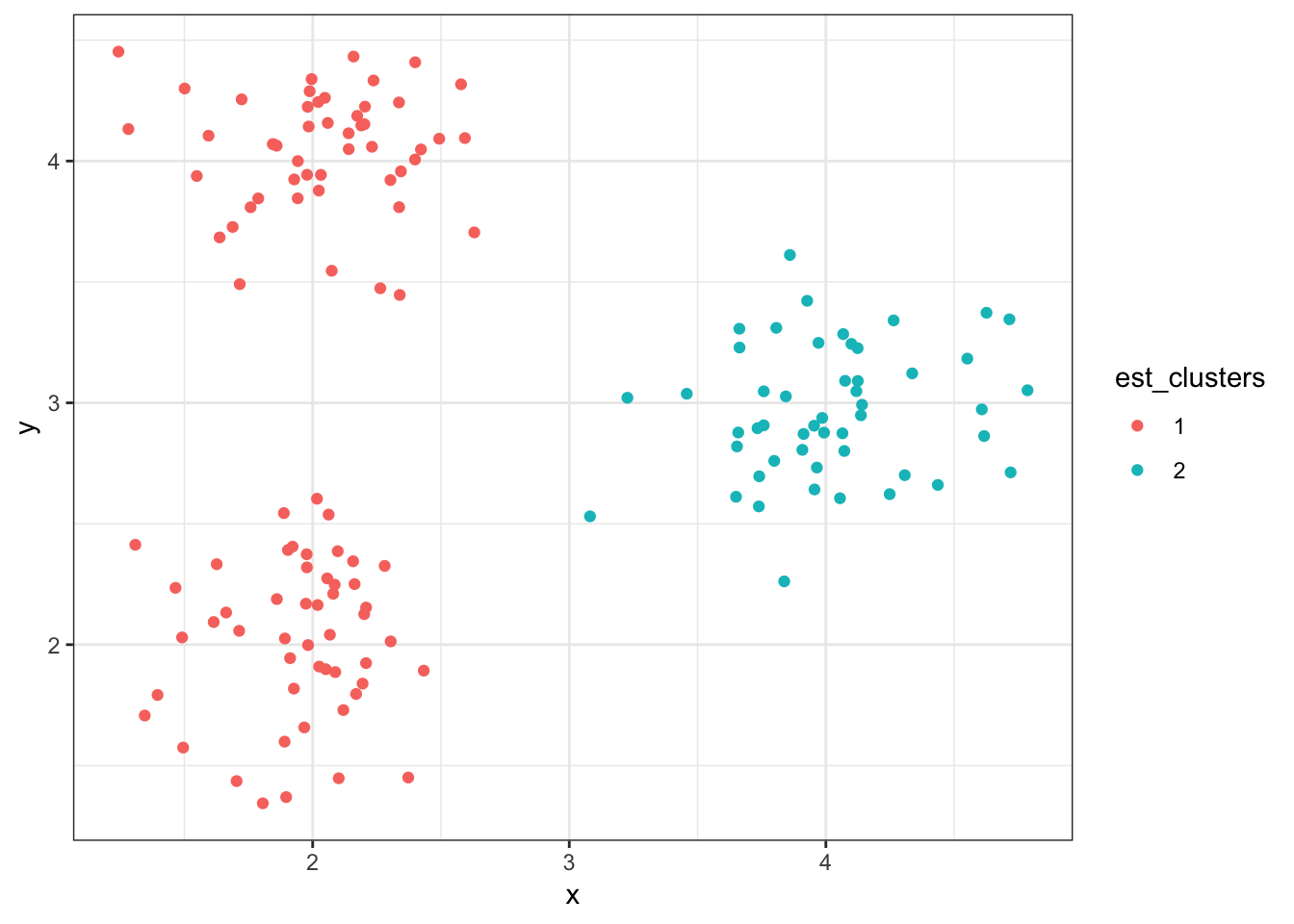
8.7.14 Cluster Assignments (\(K = 4\))
> (data1 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=4))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))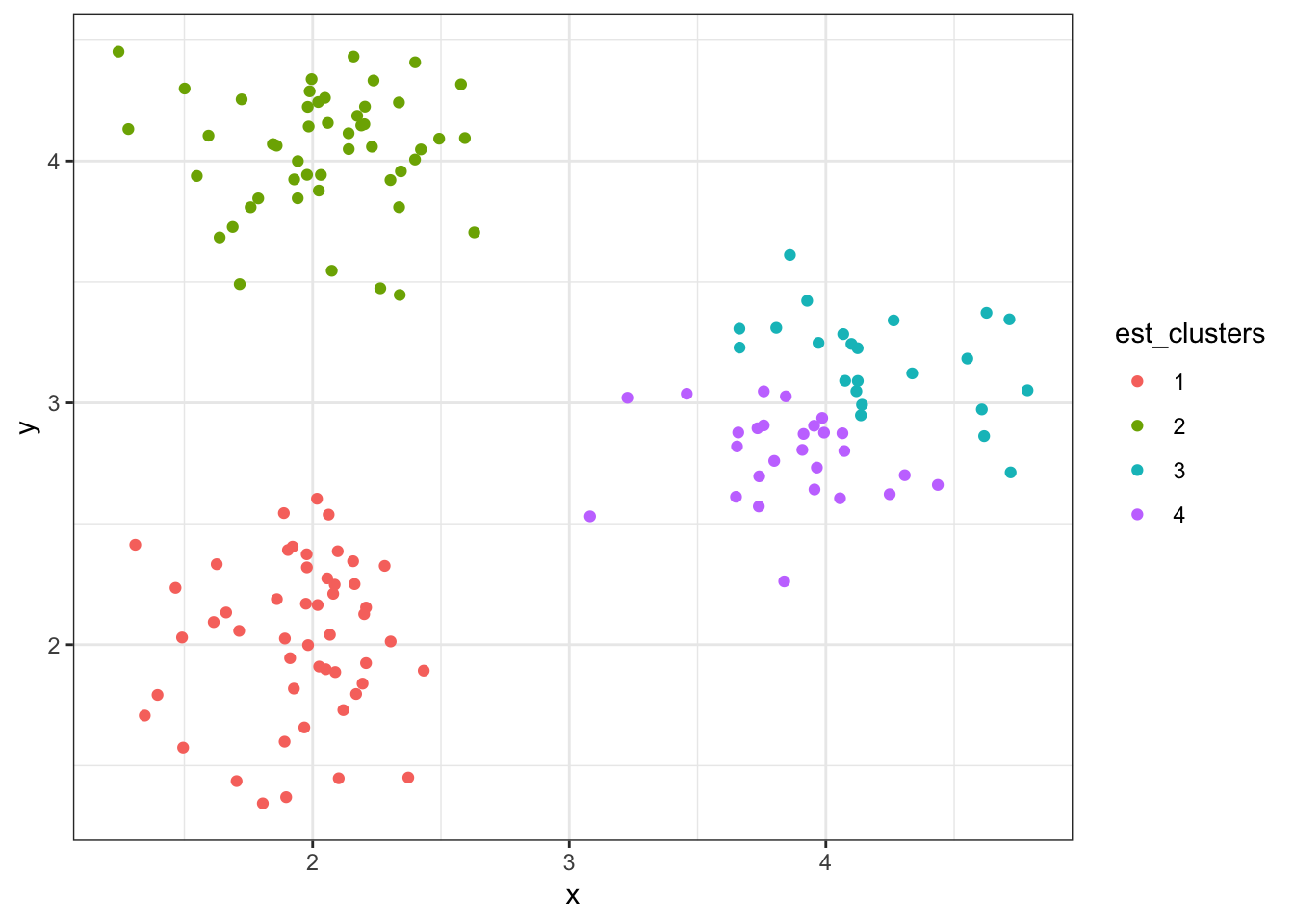
8.7.15 Cluster Assignments (\(K = 6\))
> (data1 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=6))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))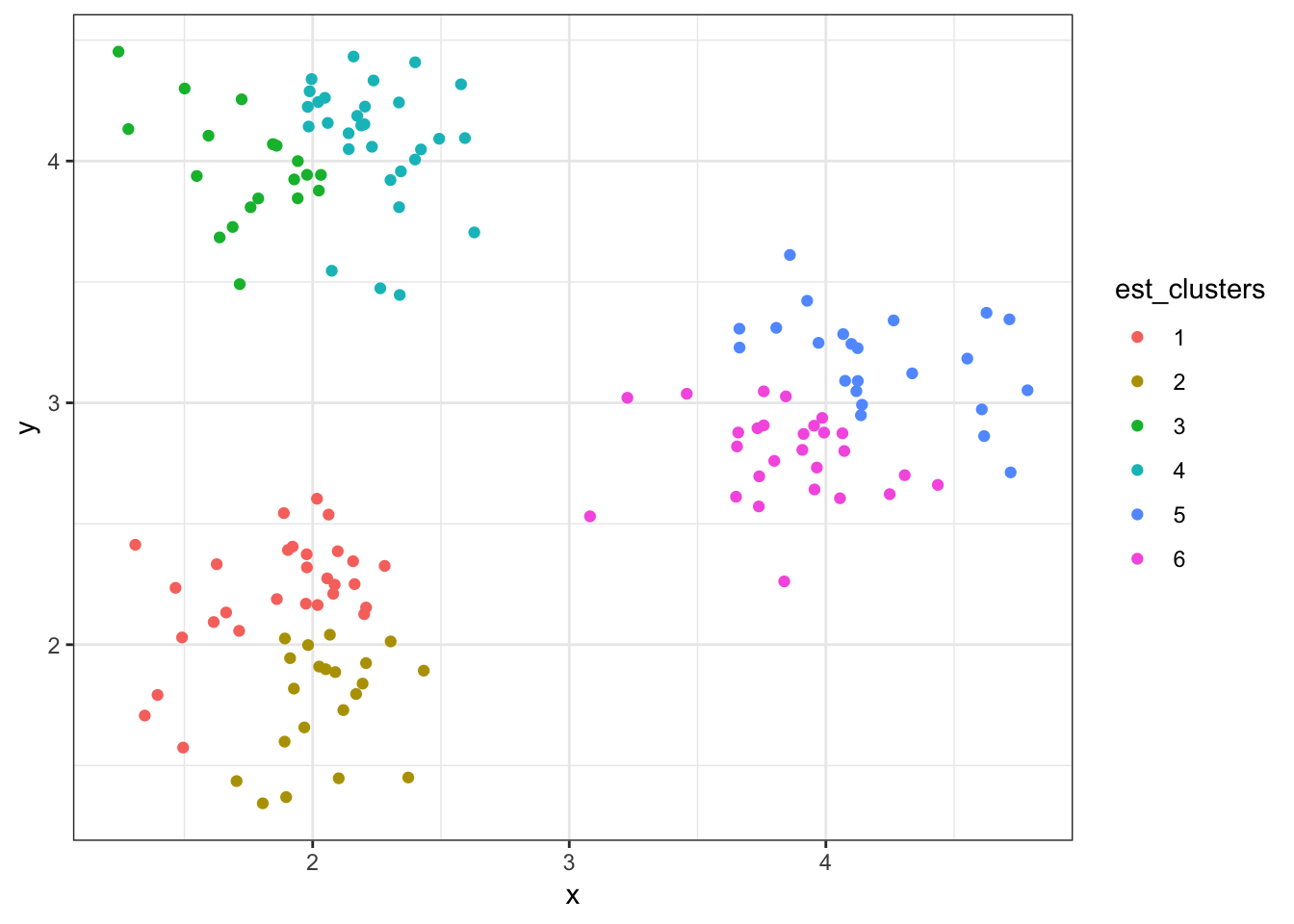
8.7.16 Linkage: Complete (Default)
> data1 %>% dist() %>% hclust(method="complete") %>%
+ as.dendrogram() %>% plot(axes=FALSE)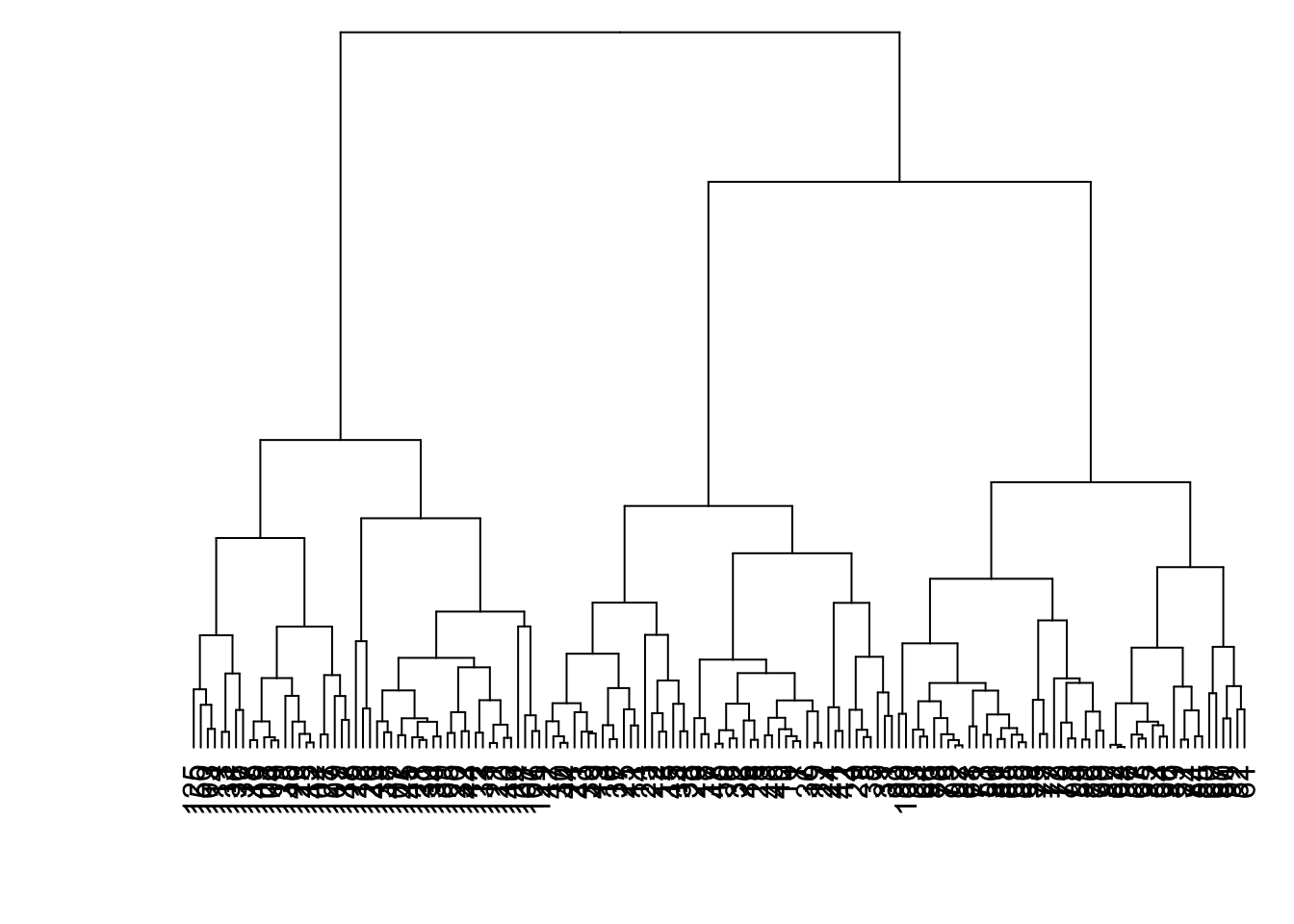
8.7.17 Linkage: Average
> data1 %>% dist() %>% hclust(method="average") %>%
+ as.dendrogram() %>% plot(axes=FALSE)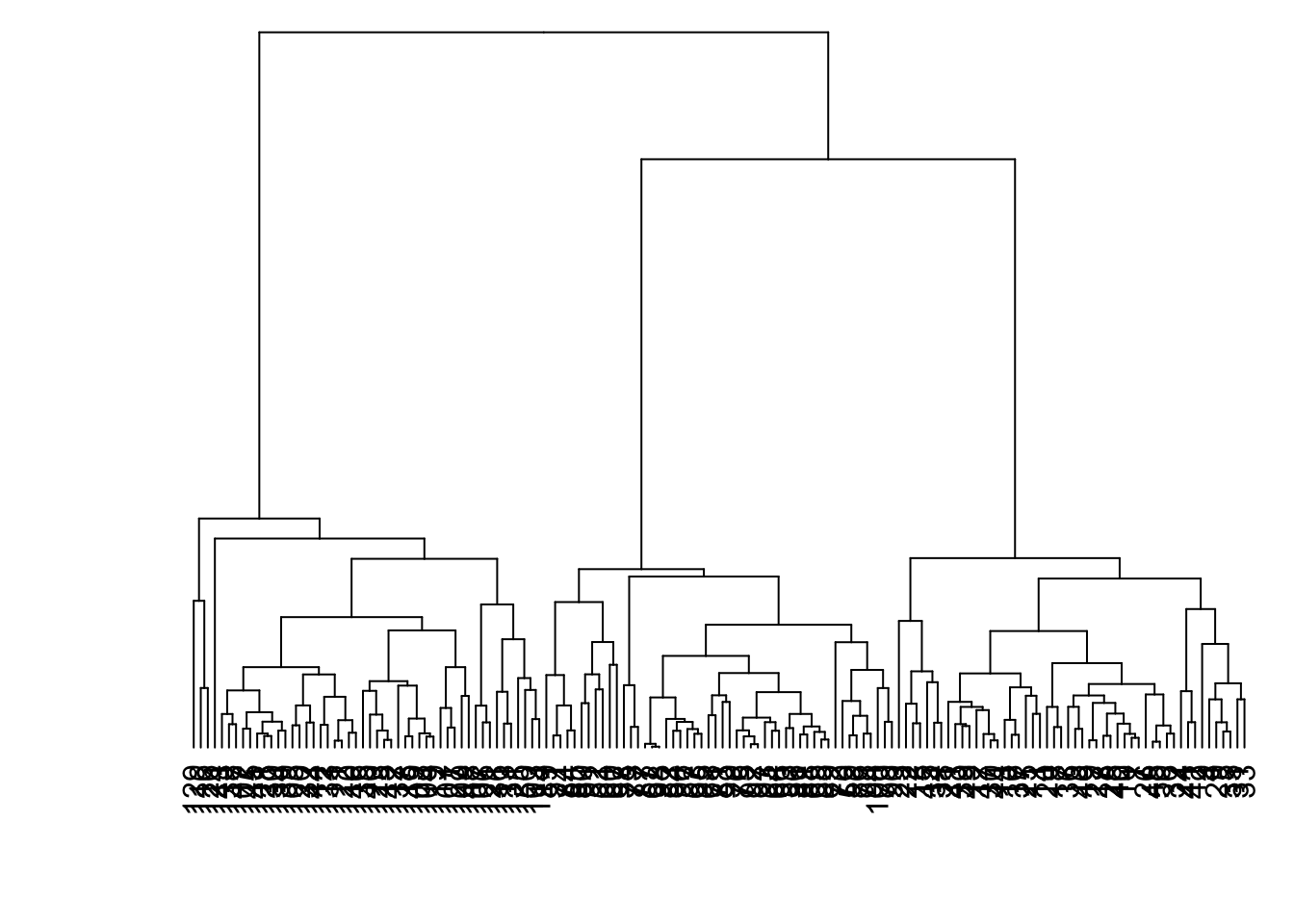
8.7.18 Linkage: Single
> data1 %>% dist() %>% hclust(method="single") %>%
+ as.dendrogram() %>% plot(axes=FALSE)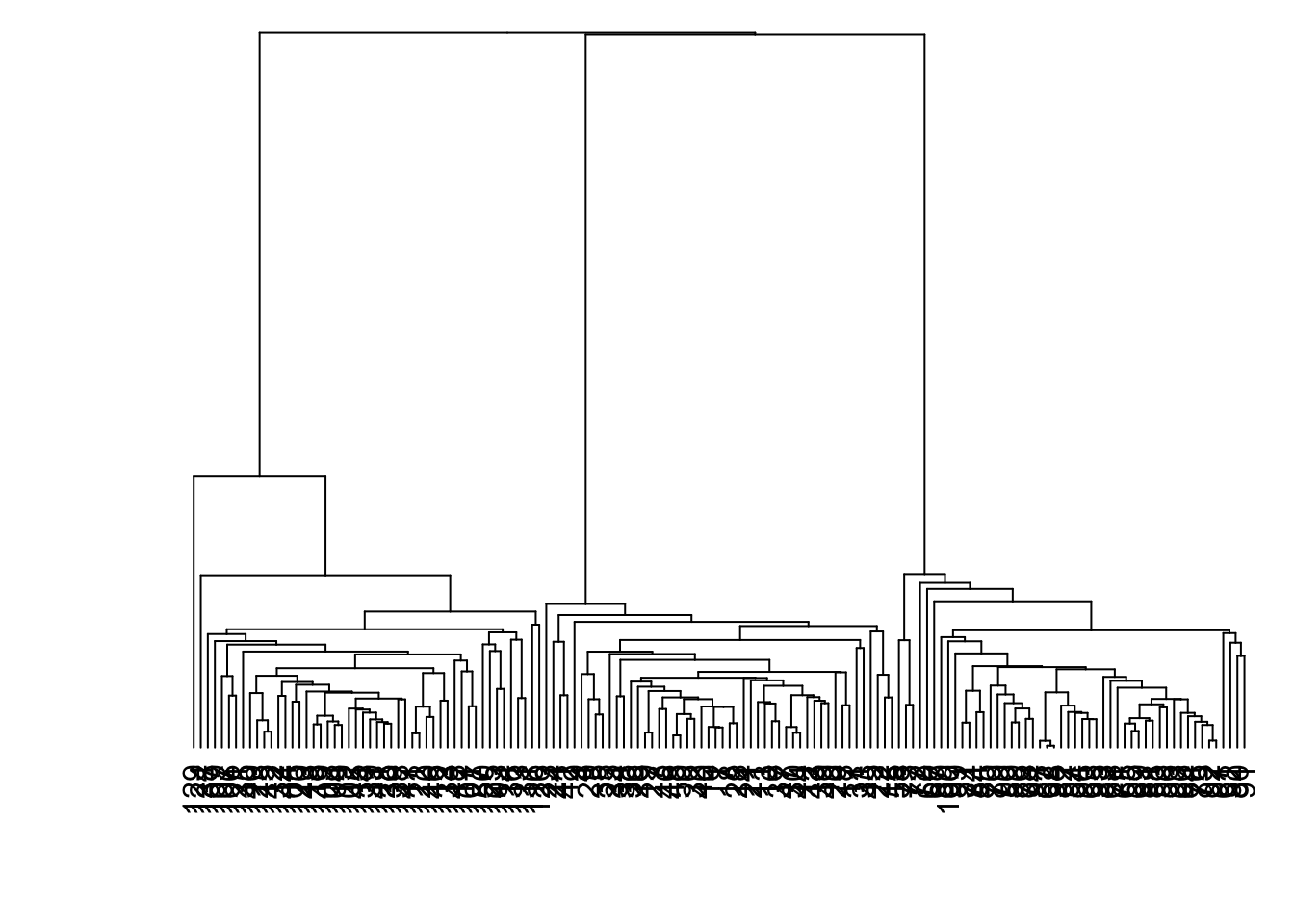
8.7.19 Linkage: Ward
> data1 %>% dist() %>% hclust(method="ward.D") %>%
+ as.dendrogram() %>% plot(axes=FALSE)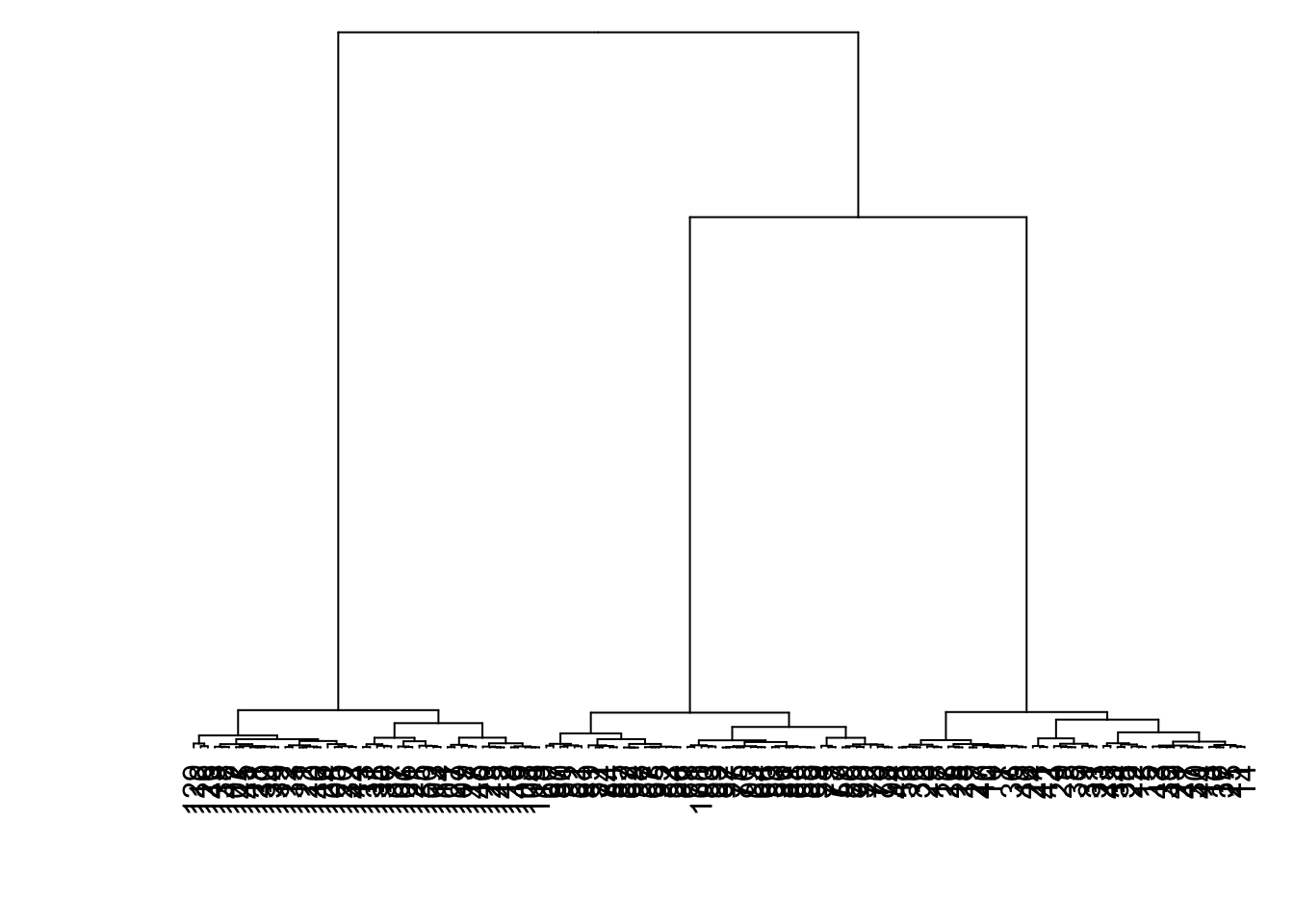
8.7.20 Hierarchical Clustering of data2
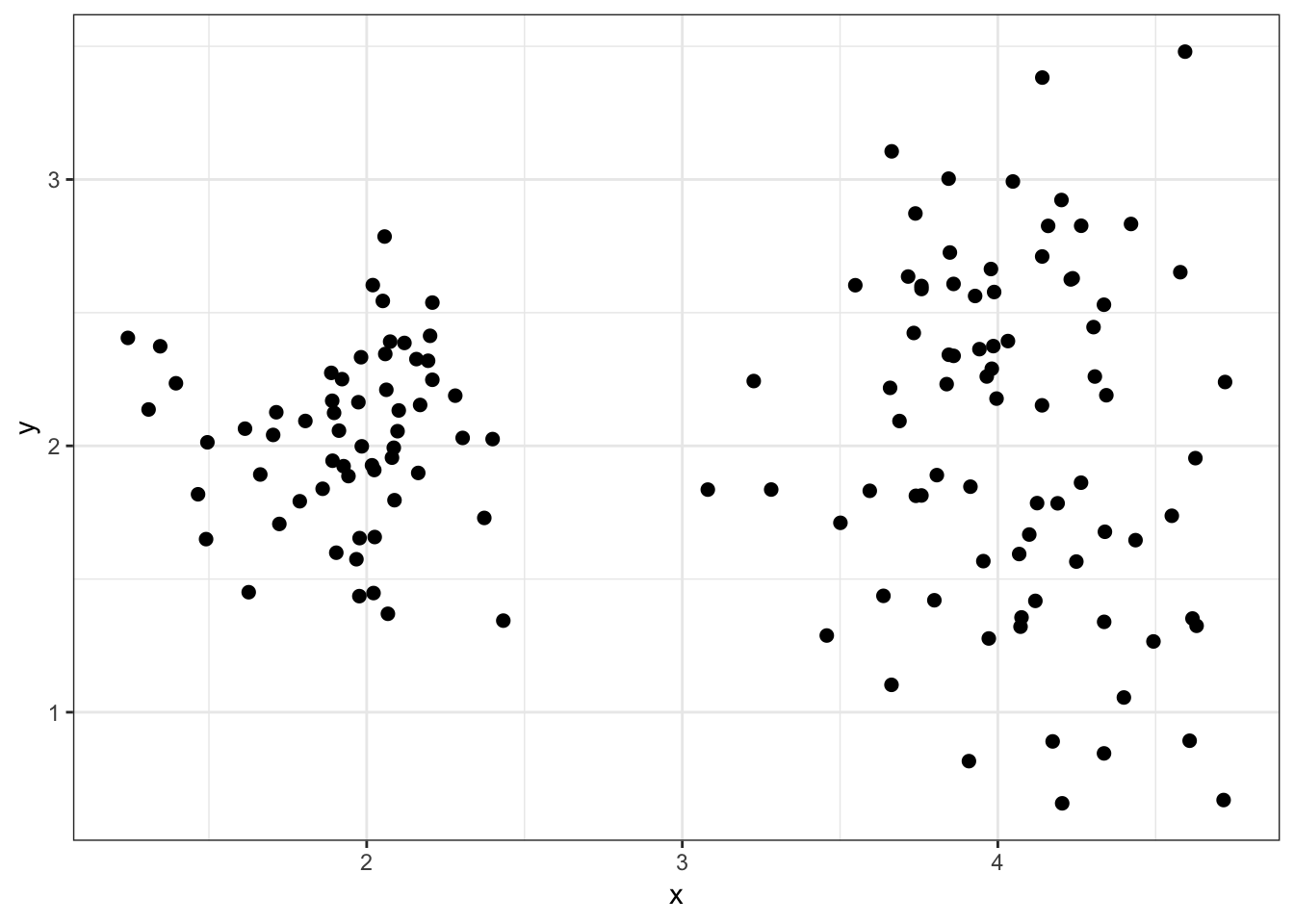
8.7.21 as.dendrogram()
> mydist <- dist(data2, method = "euclidean")
> myhclust <- hclust(mydist, method="complete")
> plot(as.dendrogram(myhclust))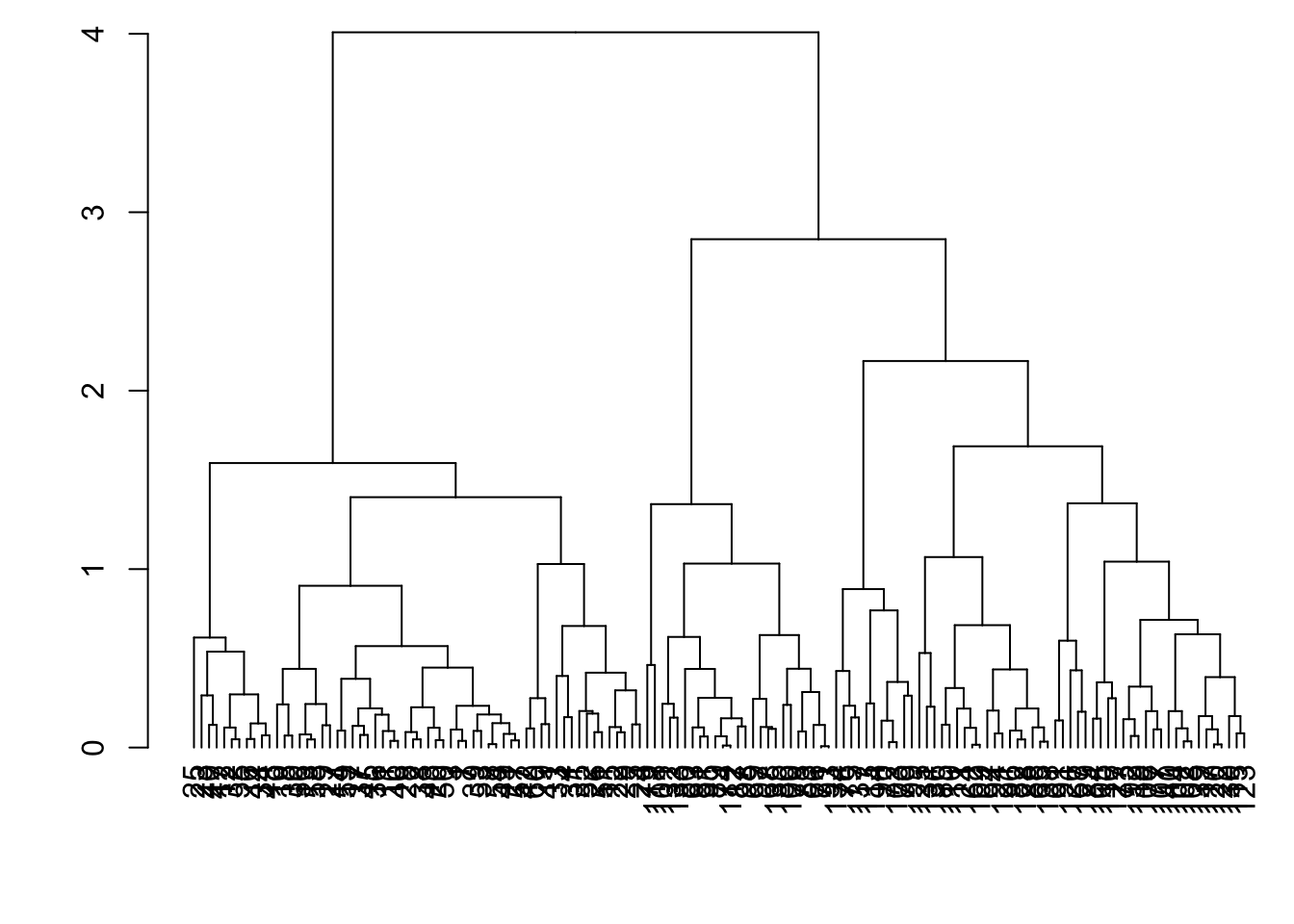
8.7.22 Modify the Labels
> library(dendextend)
> dend1 <- as.dendrogram(myhclust)
> labels(dend1) <- data2$true_clusters
> labels_colors(dend1) <-
+ c("red", "blue")[as.numeric(data2$true_clusters)]
> plot(dend1, axes=FALSE, main=" ", xlab=" ")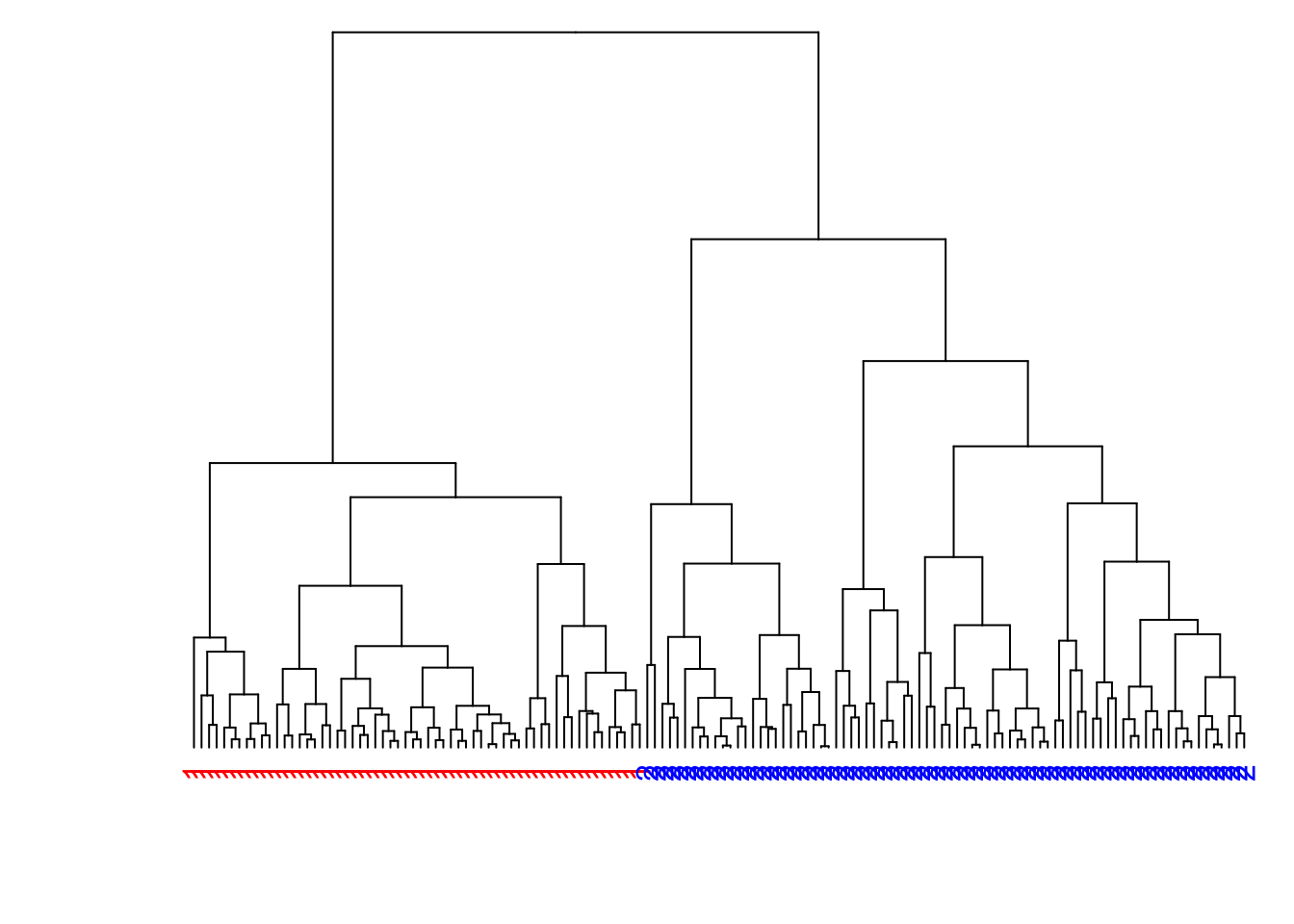
8.7.23 Color the Branches
> dend2 <- as.dendrogram(myhclust)
> labels(dend2) <- rep(" ", nrow(data2))
> dend2 <- color_branches(dend2, k = 2, col=c("red", "blue"))
> plot(dend2, axes=FALSE, main=" ", xlab=" ")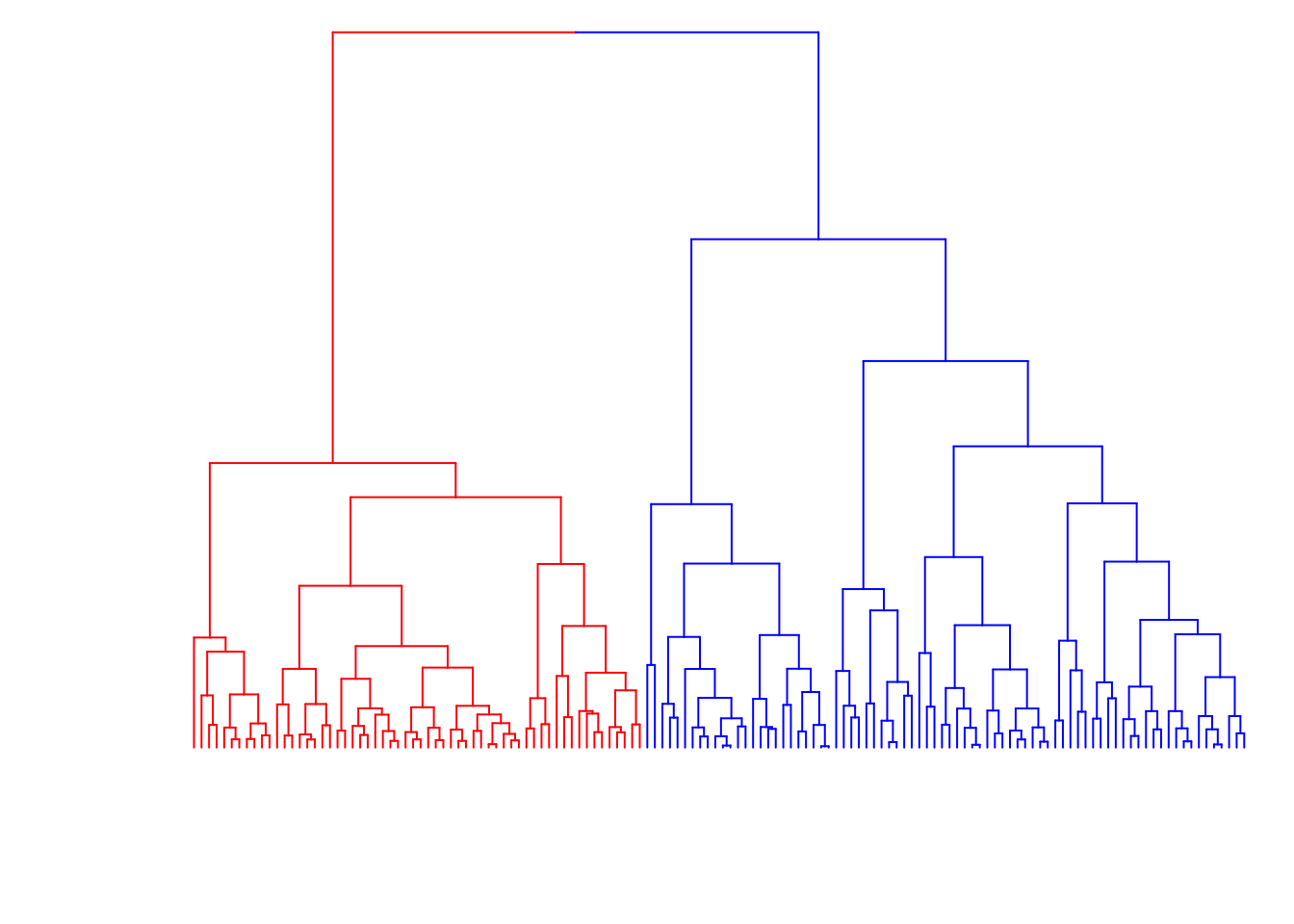
8.7.24 Cluster Assignments (\(K = 2\))
> (data2 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=2))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))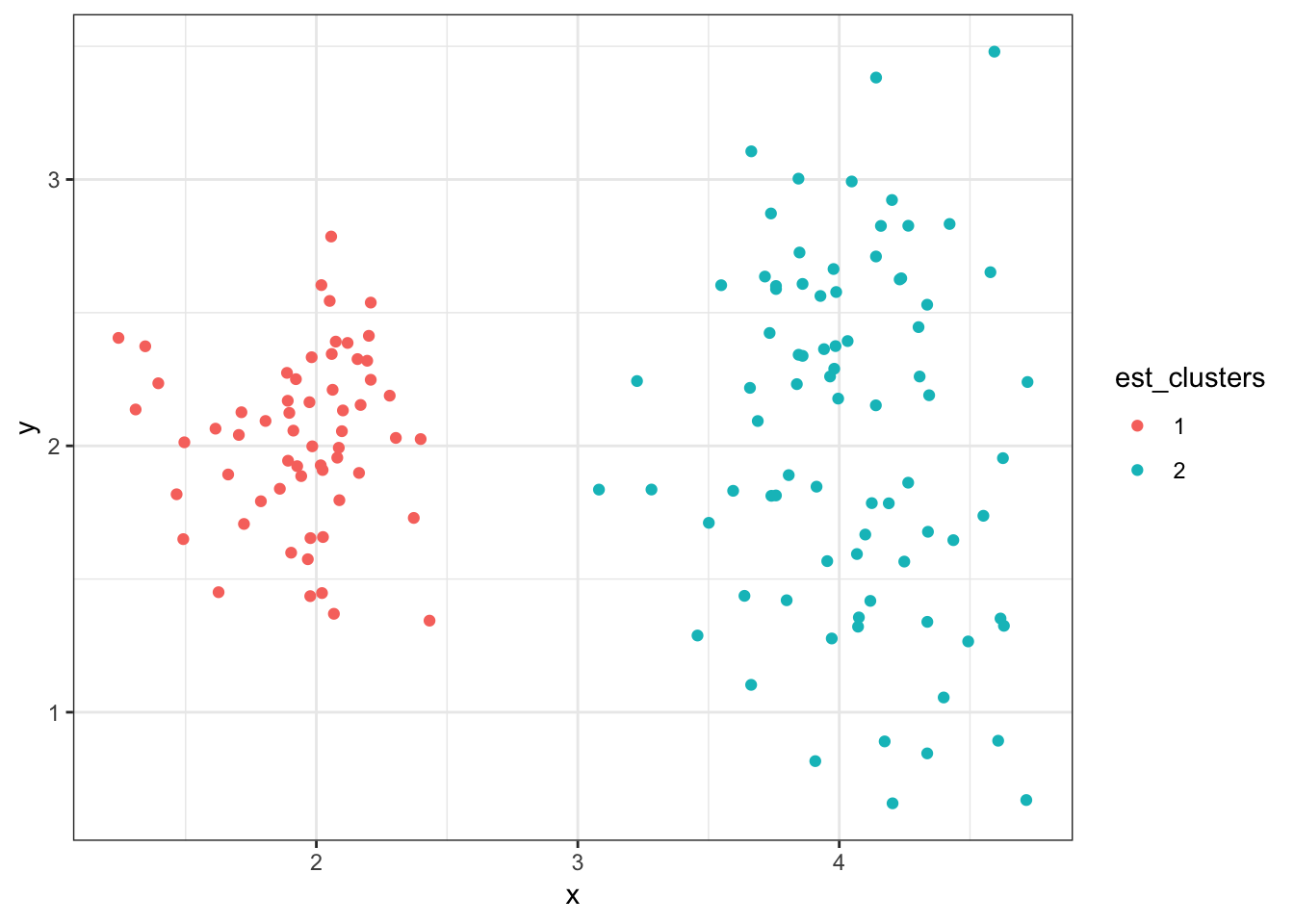
8.7.25 Cluster Assignments (\(K = 3\))
> (data2 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=3))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))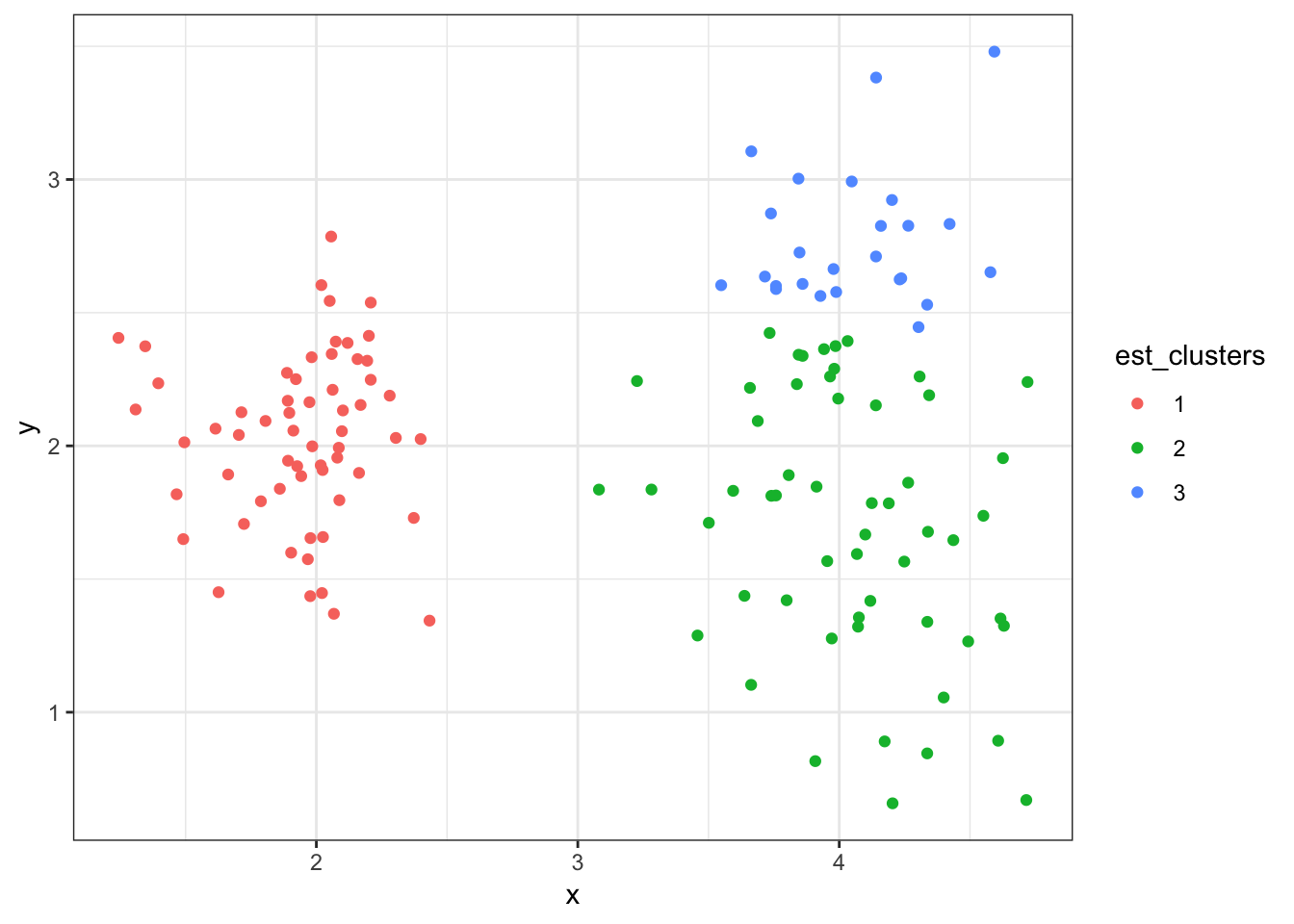
8.7.26 Cluster Assignments (\(K = 4\))
> (data2 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=4))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))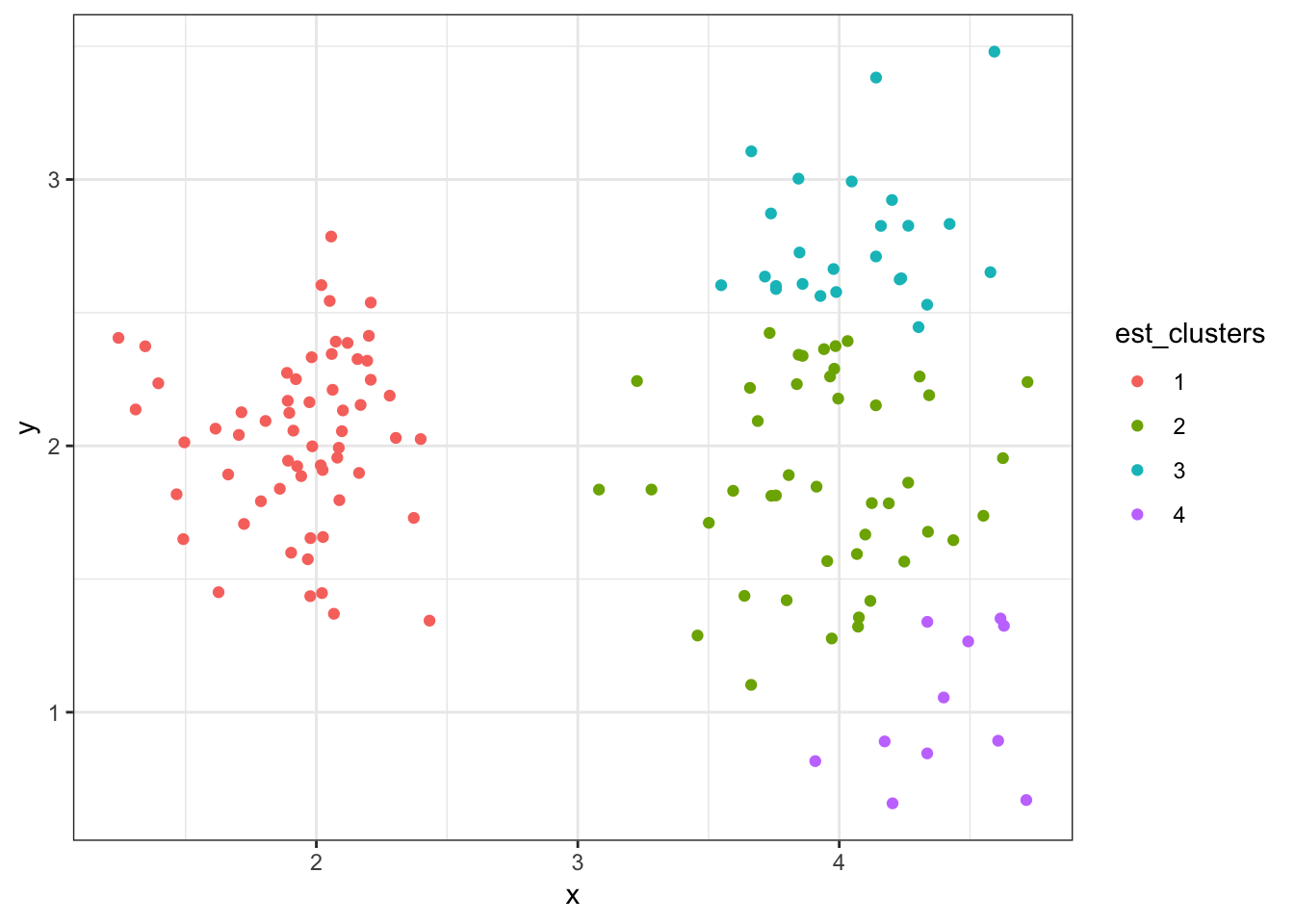
8.7.27 Cluster Assignments (\(K = 5\))
> (data2 %>%
+ mutate(est_clusters=factor(cutree(myhclust, k=6))) %>%
+ ggplot()) + geom_point(aes(x=x, y=y, color=est_clusters))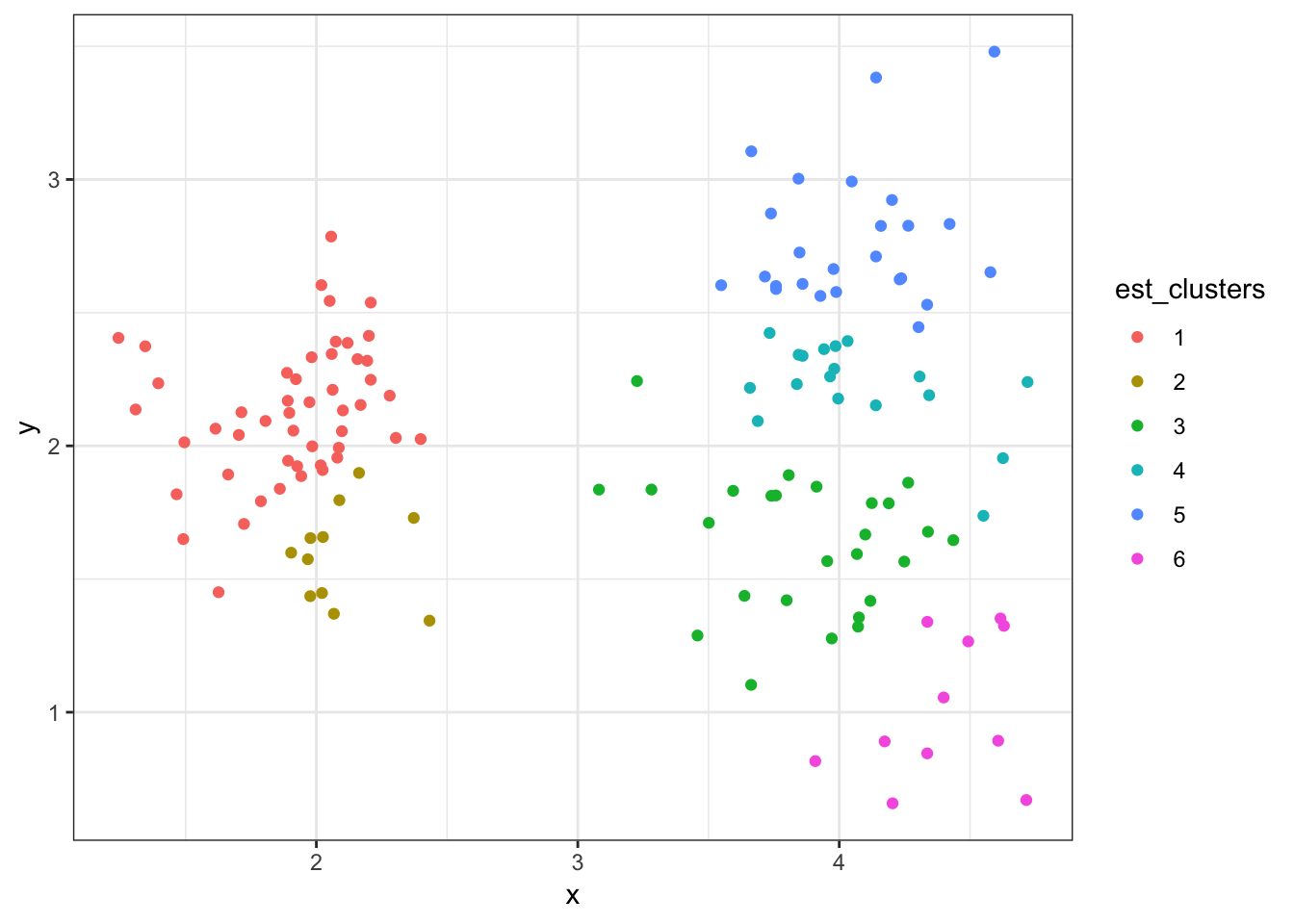
8.8 K-Means Clustering
8.8.1 Strategy
K-means clustering is a top-down, partitioning cluster analysis method that assigns each object to one of \(K\) clusters based on the distance between each object and the cluster centers, called centroids.
This is an iterative algorithm with potential random initial values.
The value of \(K\) is typically unknown and must be determined by the analyst.
8.8.2 Centroid
A centroid is the coordinate-wise average of all objects in a cluster.
Let \(A\) be a given cluster with objects \(\pmb{a} \in A\). Its centroid is:
\[\overline{\pmb{a}} = \frac{1}{|A|} \sum_{\pmb{a} \in A} \pmb{a}\]
8.8.3 Algorithm
The number of clusters \(K\) must be chosen beforehand.
- Initialize \(K\) cluster centroids.
- Assign each object to a cluster by choosing the cluster with the smalllest distance (e.g., Euclidean) between the object and the cluster centroid.
- Calculate new centroids based on the cluster assignments from Step 2.
- Repeat Steps 2–3 until convergence.
8.8.4 Notes
The initialization of the centroids is typically random, so often the algorithm is run several times with new, random initial centroids.
Convergence is usually defined in terms of neglible changes in the centroids or no changes in the cluster assignments.
8.8.5 kmeans()
K-means clustering can be accomplished through the following function:
> str(kmeans)
function (x, centers, iter.max = 10L, nstart = 1L, algorithm = c("Hartigan-Wong",
"Lloyd", "Forgy", "MacQueen"), trace = FALSE) x: the data to clusters, objects along rowscenters: either the number of clusters \(K\) or a matrix giving initial centroidsiter.max: the maximum number of iterations allowednstart: how many random intial \(K\) centroids, where the best one is returned
8.8.6 fitted()
The cluster centroids or assigments can be extracted through the function fitted(), which is applied to the output of kmeans().
The input of fitted() is the object returned by kmeans(). The key additional argument is called method.
When method="centers" it returns the centroids. When method="classes" it returns the cluster assignments.
8.8.7 K-Means Clustering of data1
> km1 <- kmeans(x=data1[,-3], centers=3, iter.max=100, nstart=5)
> est_clusters <- fitted(km1, method="classes")
> est_clusters
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[71] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 2 2 2
[106] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[141] 2 2 2 2 2 2 2 2 2 28.8.8 Centroids of data1
> centroids1 <- fitted(km1, method="centers") %>% unique()
> centroids1
x y
1 1.943184 2.028062
3 2.042872 4.037987
2 4.015934 2.962279> est_clusters <- fitted(km1, method="classes")
> data1 %>% mutate(est_clusters = factor(est_clusters)) %>%
+ group_by(est_clusters) %>% summarize(mean(x), mean(y))
# A tibble: 3 x 3
est_clusters `mean(x)` `mean(y)`
<fct> <dbl> <dbl>
1 1 1.94 2.03
2 2 4.02 2.96
3 3 2.04 4.048.8.9 Cluster Assignments (\(K = 3\))
> est_clusters <- factor(est_clusters)
> ggplot(data1) + geom_point(aes(x=x, y=y, color=est_clusters))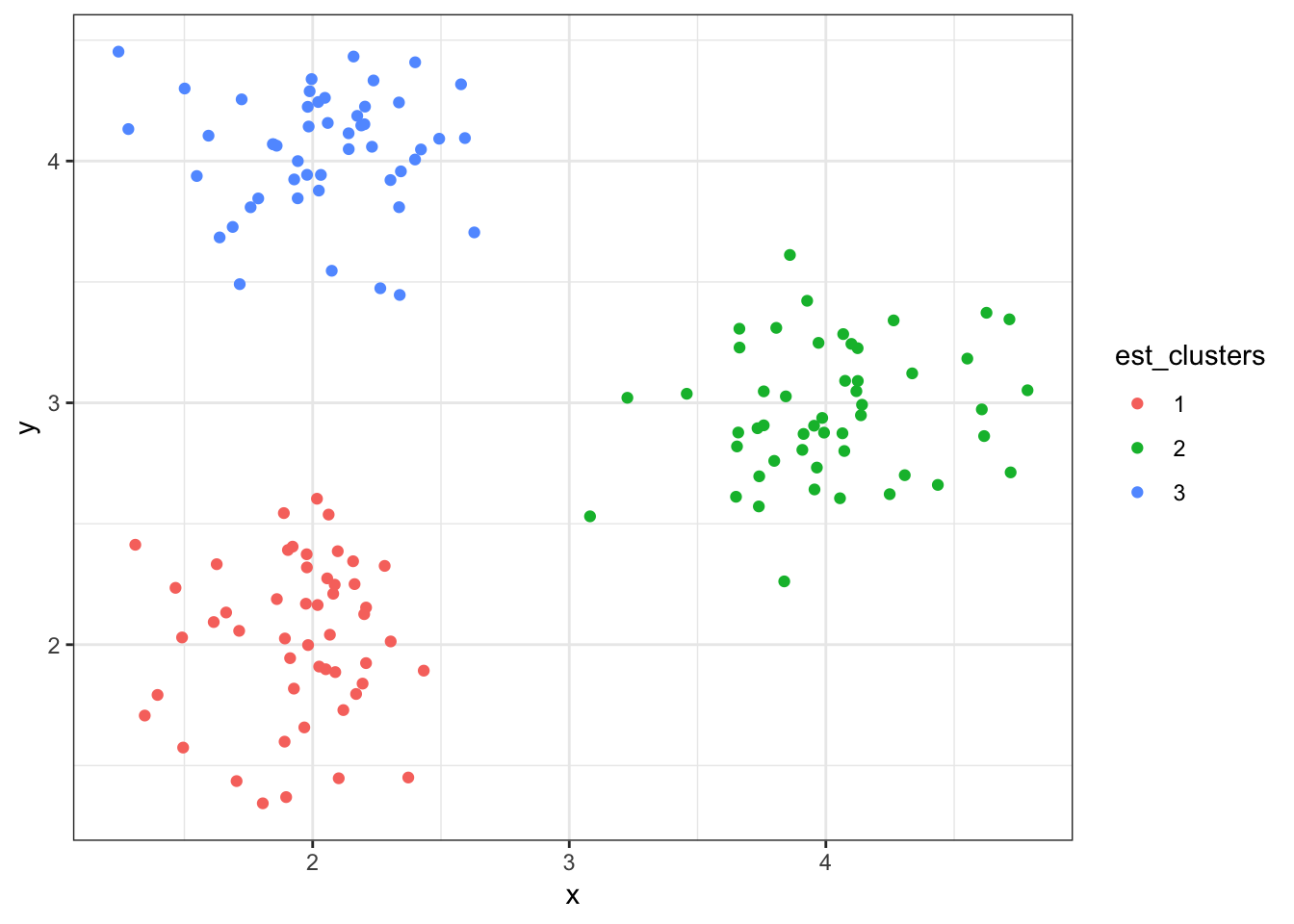
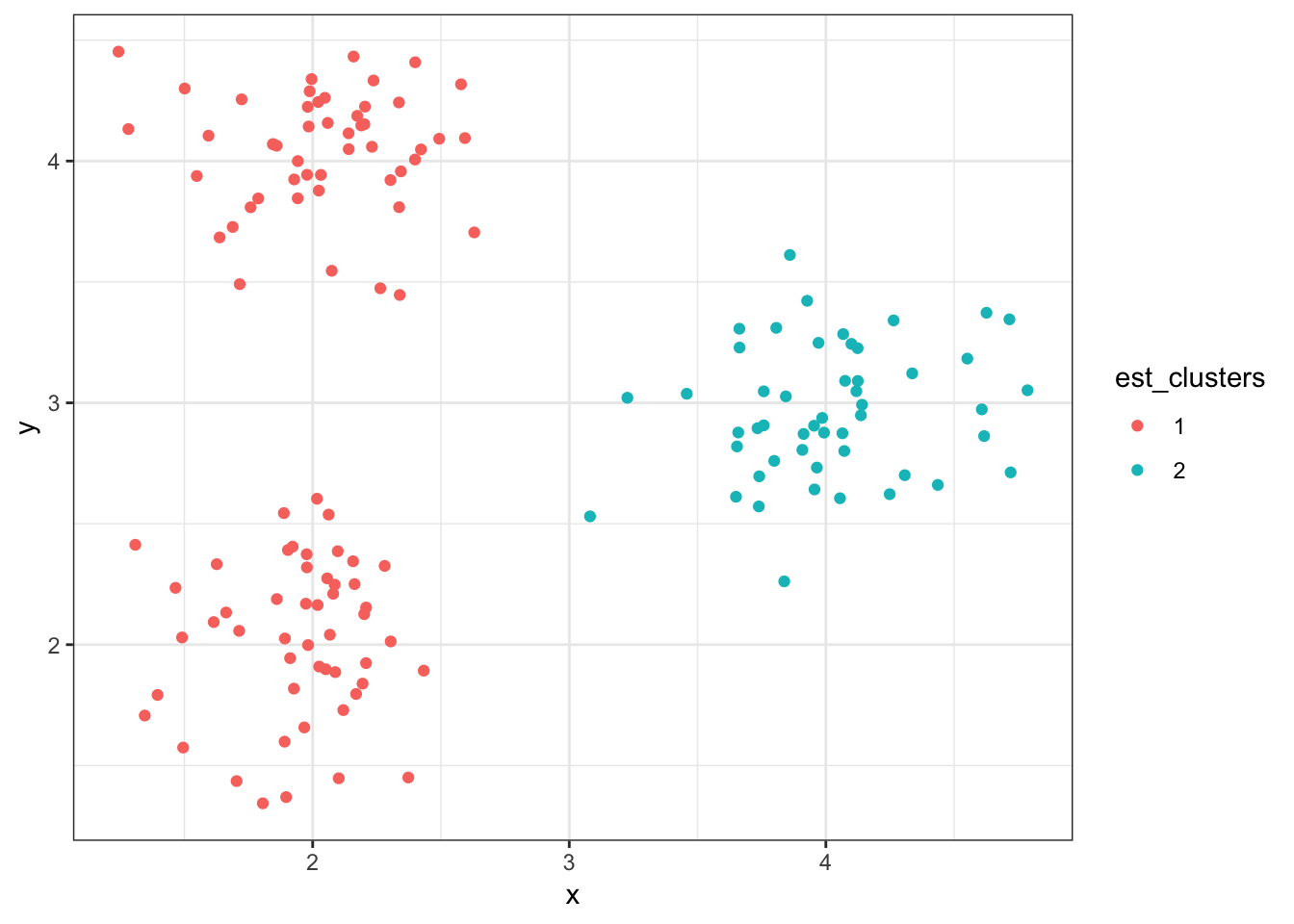
8.8.10 Cluster Assignments (\(K = 2\))
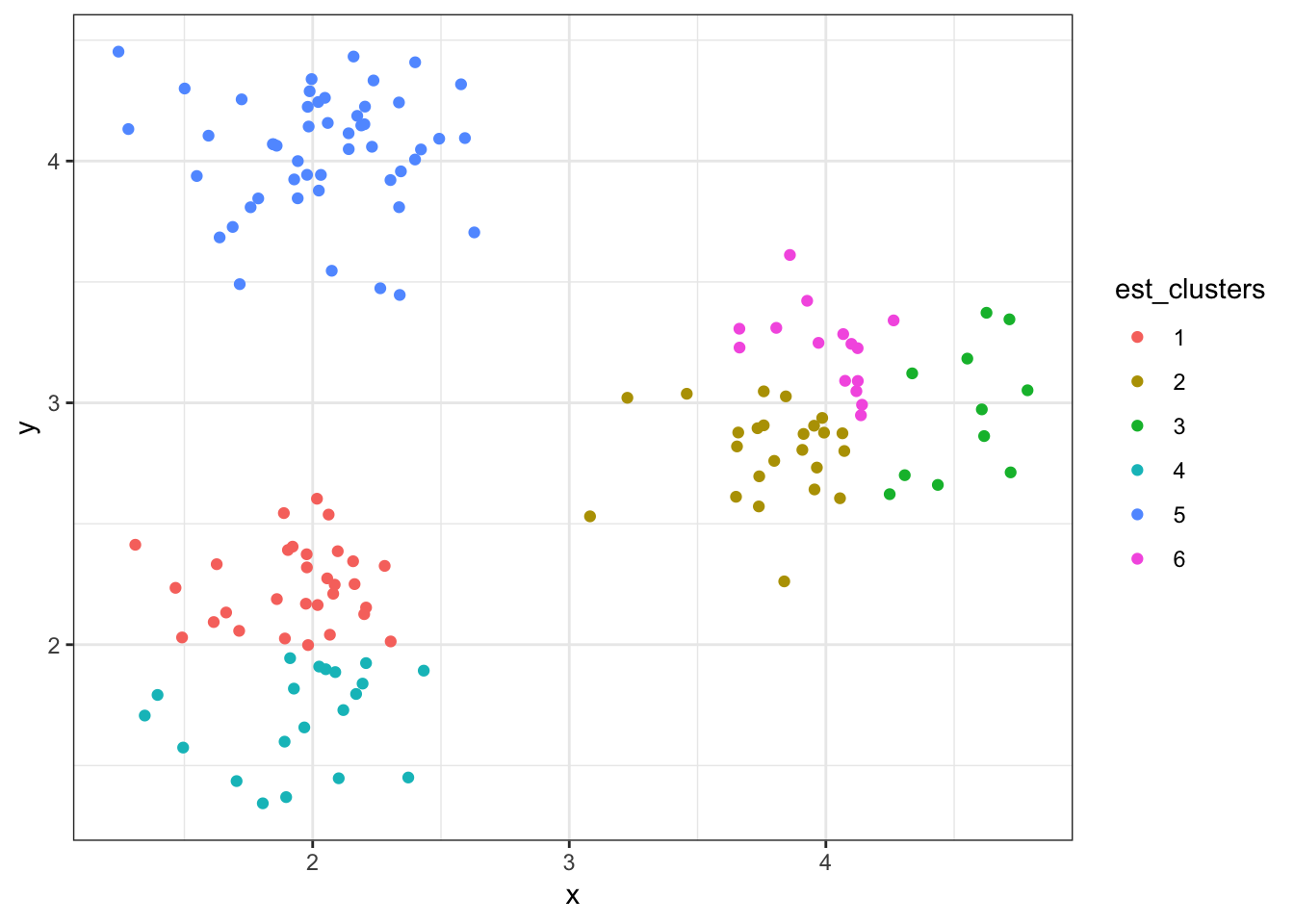
8.8.11 Cluster Assignments (\(K = 6\))
8.8.12 K-Means Clustering of data2
> km2 <- kmeans(x=data2[,-3], centers=2, iter.max=100, nstart=5)
> est_clusters <- fitted(km2, method="classes")
> est_clusters
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2
[71] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[106] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 28.8.13 Cluster Assignments (\(K = 2\))
> est_clusters <- factor(est_clusters)
> ggplot(data2) + geom_point(aes(x=x, y=y, color=est_clusters))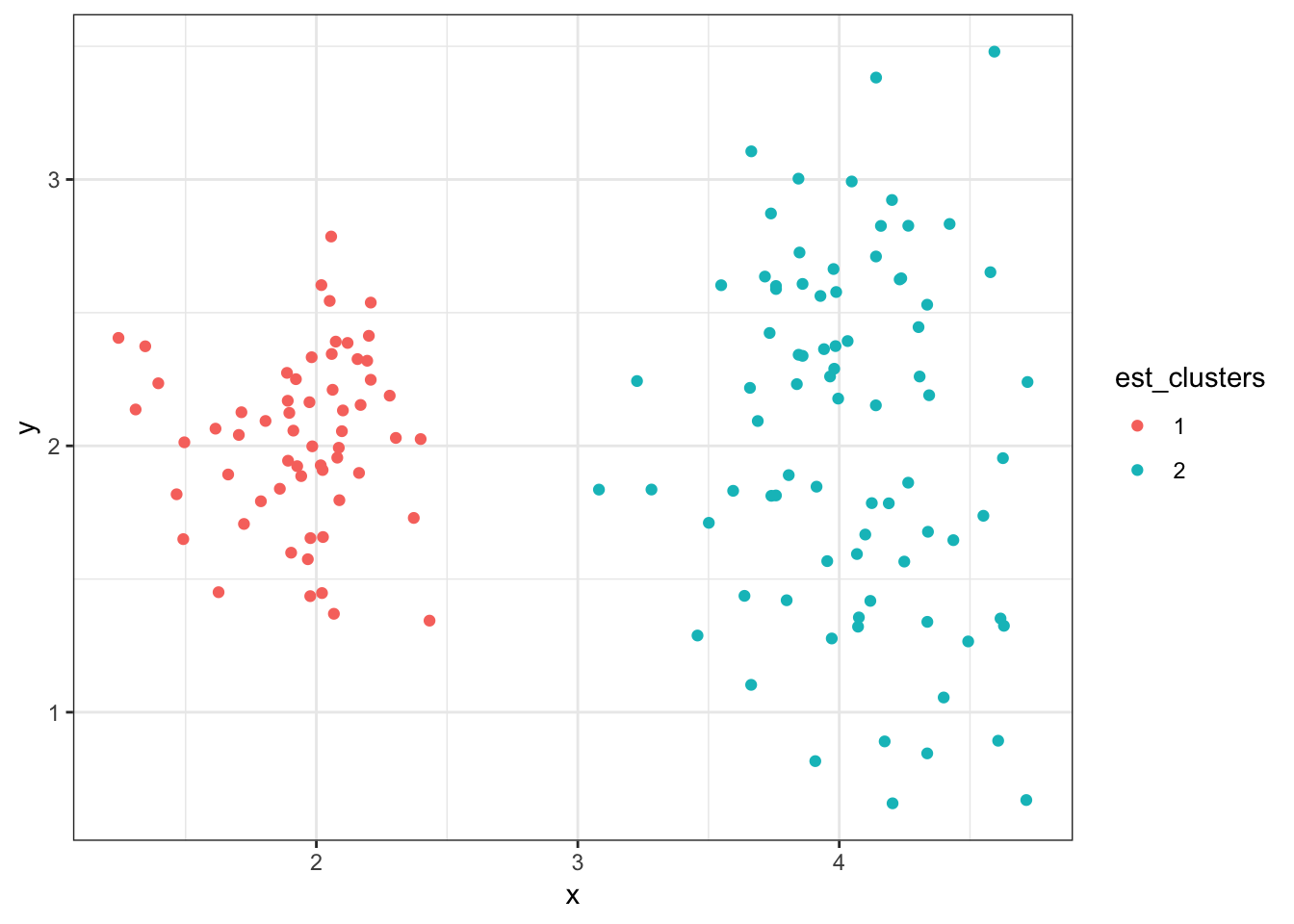
8.8.14 Cluster Assignments (\(K = 3\))
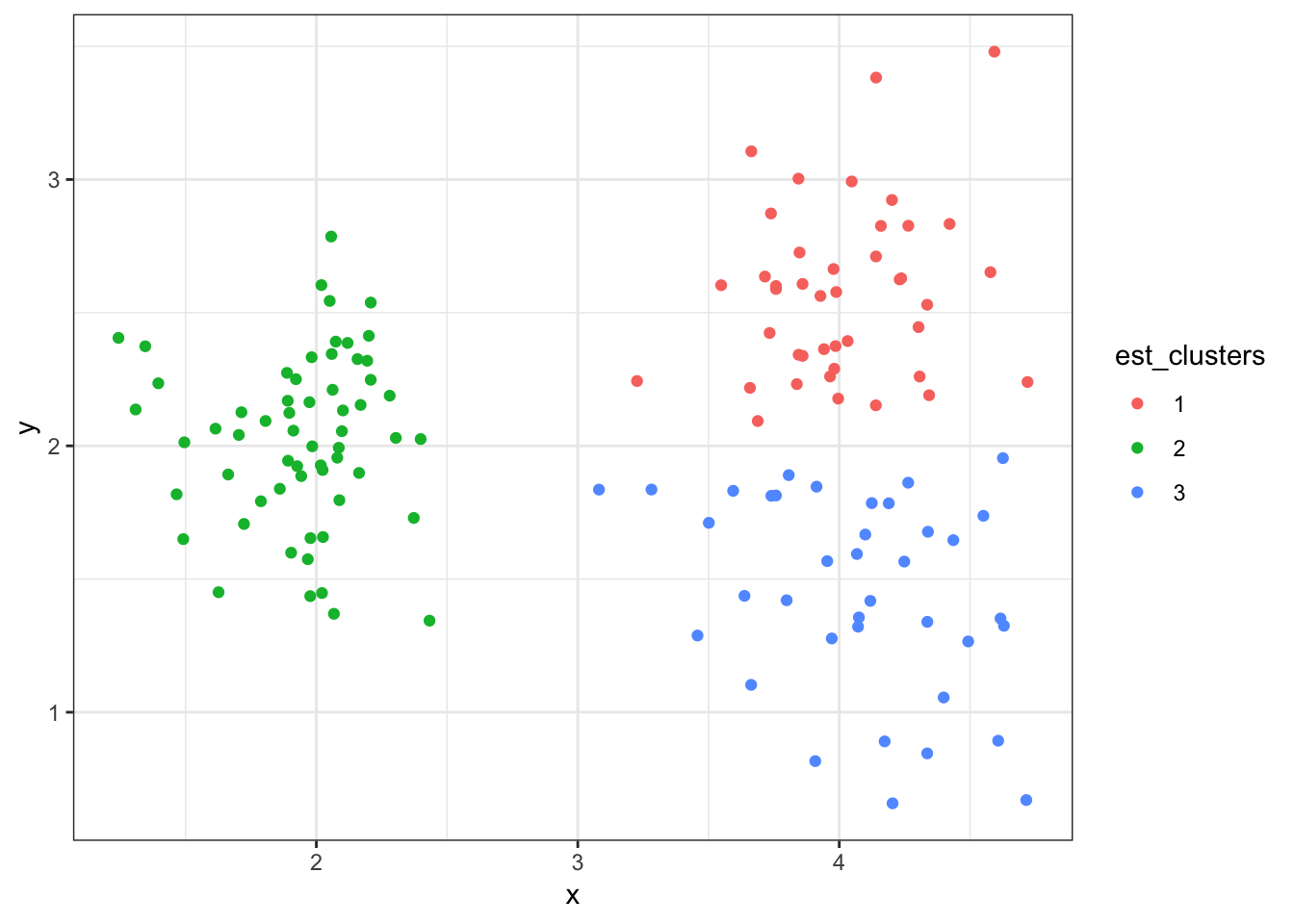
8.8.15 Cluster Assignments (\(K = 5\))