8 Transforming Data
8.1 dplyr Package
dplyr is a package with the following description:
A fast, consistent tool for working with data frame like objects, both in memory and out of memory.
This package offers a “grammar” for manipulating data frames.
Everything that dplyr does can also be done using basic R commands – however, it tends to be much faster and easier to use dplyr.
8.2 Grammar of dplyr
Verbs:
filter: extract a subset of rows from a data frame based on logical conditionsarrange: reorder rows of a data framerename: rename variables in a data frameselect: return a subset of the columns of a data frame, using a flexible notationmutate: add new variables/columns or transform existing variablesdistinct: returns only the unique values in a tablesummarize: generate summary statistics of different variables in the data frame, possibly within stratagroup_by: breaks down a dataset into specified groups of rows
Partially based on R Programming for Data Science
8.3 Baby Names Data Set
> library("dplyr", verbose=FALSE)
> library("babynames")
> ls()
character(0)
> babynames <- as_tibble(babynames::babynames)
> ls()
[1] "babynames"The babynames Object
> class(babynames)
[1] "tbl_df" "tbl" "data.frame"
> dim(babynames)
[1] 1924665 5> babynames
# A tibble: 1,924,665 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# … with 1,924,655 more rowsPeek at the Data
> set.seed(201)
> sample_n(babynames, 10)
# A tibble: 10 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1994 M Kael 16 0.00000785
2 1989 F Nafeesah 6 0.00000301
3 2017 M Yireh 5 0.00000255
4 1976 M Marrio 11 0.00000674
5 2008 M Kerolos 9 0.00000413
6 1993 F Claire 1895 0.000961
7 2002 F Rubit 5 0.00000253
8 2006 F Kaija 26 0.0000124
9 1990 F Leshae 7 0.00000341
10 1940 F Vernell 146 0.000124
> ## try also sample_frac(babynames, 6e-6)8.4 %>% Operator
Originally from R package magrittr. Provides a mechanism for chaining commands with a forward-pipe operator, %>%.
> x <- 1:10
>
> x %>% log(base=10) %>% sum()
[1] 6.559763
>
> sum(log(x,base=10))
[1] 6.559763> babynames %>% sample_n(5)
# A tibble: 5 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1974 F Greer 14 0.00000894
2 1933 M Porter 68 0.0000667
3 2004 M Jacobo 69 0.0000327
4 1987 F Morgaine 7 0.00000374
5 1947 F Bonnye 22 0.0000121 8.5 filter()
> filter(babynames, year==1880, sex=="F")
# A tibble: 942 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# … with 932 more rows
> ## same as filter(babynames, year==1880 & sex=="F")> filter(babynames, year==1880, sex=="F", n > 5000)
# A tibble: 1 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.07248.6 arrange()
> arrange(babynames, name, year, sex)
# A tibble: 1,924,665 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 2007 M Aaban 5 0.00000226
2 2009 M Aaban 6 0.00000283
3 2010 M Aaban 9 0.00000439
4 2011 M Aaban 11 0.00000542
5 2012 M Aaban 11 0.00000543
6 2013 M Aaban 14 0.00000694
7 2014 M Aaban 16 0.00000783
8 2015 M Aaban 15 0.00000736
9 2016 M Aaban 9 0.00000446
10 2017 M Aaban 11 0.0000056
# … with 1,924,655 more rows> arrange(babynames, desc(name), desc(year), sex)
# A tibble: 1,924,665 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 2010 M Zzyzx 5 0.00000244
2 2014 M Zyyon 6 0.00000293
3 2010 F Zyyanna 6 0.00000306
4 2015 M Zyvon 7 0.00000343
5 2009 M Zyvion 5 0.00000236
6 2017 F Zyva 9 0.0000048
7 2016 F Zyva 8 0.00000415
8 2015 M Zyus 5 0.00000245
9 2010 M Zytavious 6 0.00000292
10 2009 M Zytavious 7 0.0000033
# … with 1,924,655 more rows8.7 rename()
> rename(babynames, number=n)
# A tibble: 1,924,665 x 5
year sex name number prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# … with 1,924,655 more rows8.8 select()
> select(babynames, sex, name, n)
# A tibble: 1,924,665 x 3
sex name n
<chr> <chr> <int>
1 F Mary 7065
2 F Anna 2604
3 F Emma 2003
4 F Elizabeth 1939
5 F Minnie 1746
6 F Margaret 1578
7 F Ida 1472
8 F Alice 1414
9 F Bertha 1320
10 F Sarah 1288
# … with 1,924,655 more rows
> ## same as select(babynames, sex:n)Renaming with select():
> select(babynames, sex, name, number=n)
# A tibble: 1,924,665 x 3
sex name number
<chr> <chr> <int>
1 F Mary 7065
2 F Anna 2604
3 F Emma 2003
4 F Elizabeth 1939
5 F Minnie 1746
6 F Margaret 1578
7 F Ida 1472
8 F Alice 1414
9 F Bertha 1320
10 F Sarah 1288
# … with 1,924,655 more rows8.9 mutate()
> mutate(babynames, total_by_year=round(n/prop))
# A tibble: 1,924,665 x 6
year sex name n prop total_by_year
<dbl> <chr> <chr> <int> <dbl> <dbl>
1 1880 F Mary 7065 0.0724 97605
2 1880 F Anna 2604 0.0267 97605
3 1880 F Emma 2003 0.0205 97605
4 1880 F Elizabeth 1939 0.0199 97605
5 1880 F Minnie 1746 0.0179 97605
6 1880 F Margaret 1578 0.0162 97605
7 1880 F Ida 1472 0.0151 97605
8 1880 F Alice 1414 0.0145 97605
9 1880 F Bertha 1320 0.0135 97605
10 1880 F Sarah 1288 0.0132 97605
# … with 1,924,655 more rows
> ## see also transmutate8.10 distinct()
Let’s put a few things together now adding the function distinct()…
> babynames %>% mutate(total_by_year=round(n/prop)) %>%
+ select(sex, year, total_by_year) %>% distinct()
# A tibble: 36,099 x 3
sex year total_by_year
<chr> <dbl> <dbl>
1 F 1880 97605
2 F 1880 97604
3 F 1880 97606
4 F 1880 97603
5 F 1880 97607
6 F 1880 97602
7 F 1880 97609
8 F 1880 97599
9 M 1880 118400
10 M 1880 118399
# … with 36,089 more rows8.11 summarize()
> summarize(babynames, mean_n = mean(n), median_n = median(n),
+ number_sex = n_distinct(sex),
+ distinct_names = n_distinct(name))
# A tibble: 1 x 4
mean_n median_n number_sex distinct_names
<dbl> <int> <int> <int>
1 181. 12 2 973108.12 group_by()
> babynames %>% group_by(year, sex)
# A tibble: 1,924,665 x 5
# Groups: year, sex [276]
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# … with 1,924,655 more rows8.13 Chaining Verbs Together
No. Individuals by Year and Sex
> babynames %>% group_by(year, sex) %>%
+ summarize(total_by_year=sum(n))
# A tibble: 276 x 3
# Groups: year [138]
year sex total_by_year
<dbl> <chr> <int>
1 1880 F 90993
2 1880 M 110491
3 1881 F 91953
4 1881 M 100743
5 1882 F 107847
6 1882 M 113686
7 1883 F 112319
8 1883 M 104627
9 1884 F 129020
10 1884 M 114442
# … with 266 more rowsHow Many Distinct Names?
> babynames %>% group_by(sex) %>%
+ summarize(mean_n = mean(n),
+ distinct_names_sex = n_distinct(name))
# A tibble: 2 x 3
sex mean_n distinct_names_sex
<chr> <dbl> <int>
1 F 151. 67046
2 M 223. 40927Most Popular Names by Year
> top_names <- babynames %>% group_by(year, sex) %>%
+ summarize(top_name = name[which.max(n)])
>
> head(top_names)
# A tibble: 6 x 3
# Groups: year [3]
year sex top_name
<dbl> <chr> <chr>
1 1880 F Mary
2 1880 M John
3 1881 F Mary
4 1881 M John
5 1882 F Mary
6 1882 M John Most Popular Names in Recent Years
> tail(top_names, n=10)
# A tibble: 10 x 3
# Groups: year [5]
year sex top_name
<dbl> <chr> <chr>
1 2013 F Sophia
2 2013 M Noah
3 2014 F Emma
4 2014 M Noah
5 2015 F Emma
6 2015 M Noah
7 2016 F Emma
8 2016 M Noah
9 2017 F Emma
10 2017 M Liam Most Popular Female Names in the 1990s
> top_names %>% filter(year >= 1990 & year < 2000, sex=="F")
# A tibble: 10 x 3
# Groups: year [10]
year sex top_name
<dbl> <chr> <chr>
1 1990 F Jessica
2 1991 F Ashley
3 1992 F Ashley
4 1993 F Jessica
5 1994 F Jessica
6 1995 F Jessica
7 1996 F Emily
8 1997 F Emily
9 1998 F Emily
10 1999 F Emily Most Popular Male Names in the 1990s
> top_names %>% filter(year >= 1990 & year < 2000, sex=="M")
# A tibble: 10 x 3
# Groups: year [10]
year sex top_name
<dbl> <chr> <chr>
1 1990 M Michael
2 1991 M Michael
3 1992 M Michael
4 1993 M Michael
5 1994 M Michael
6 1995 M Michael
7 1996 M Michael
8 1997 M Michael
9 1998 M Michael
10 1999 M Jacob Analyzing the name ‘John’
> john <- babynames %>% filter(sex=="M", name=="John")
> plot(john$year, john$prop, type="l")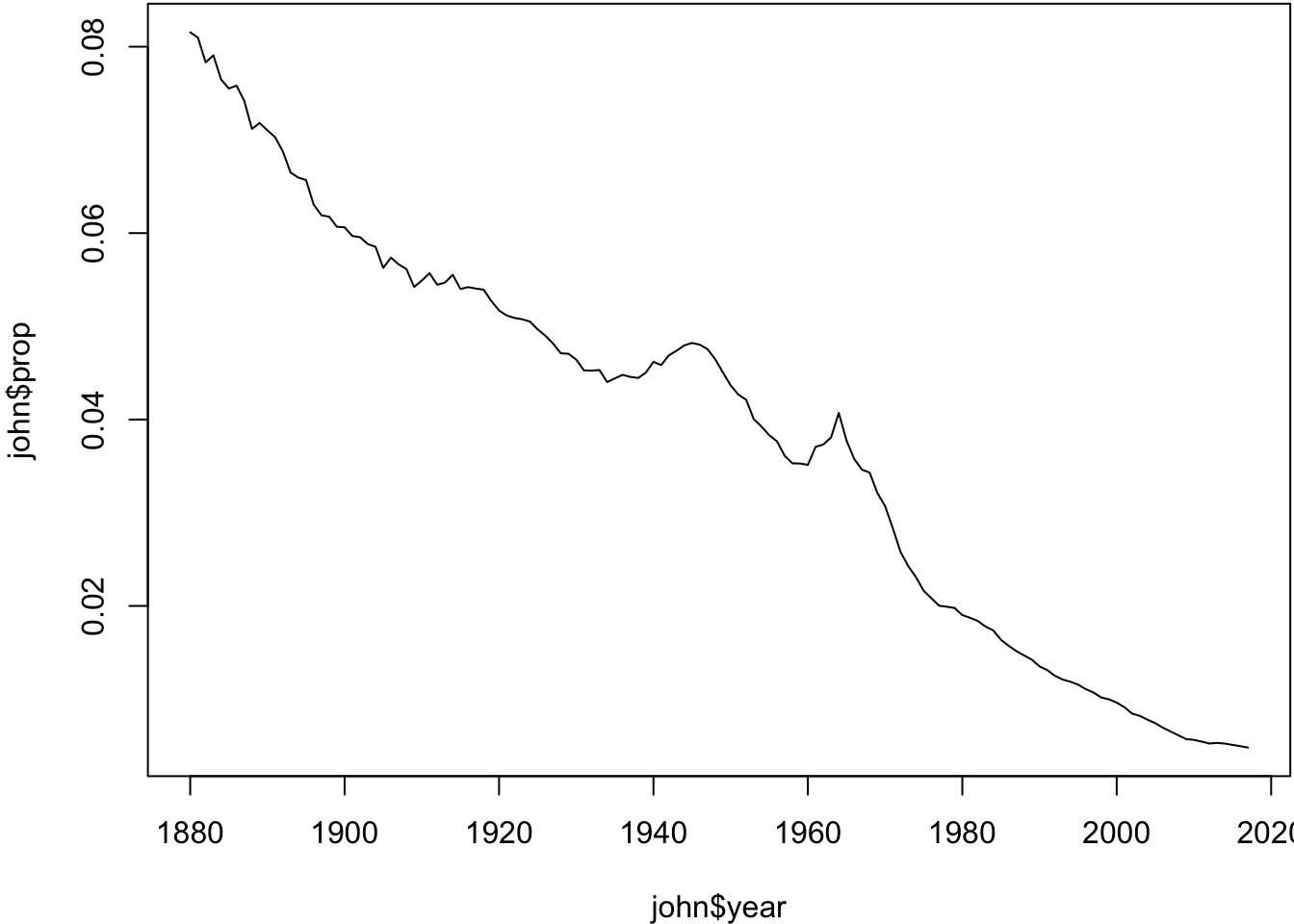
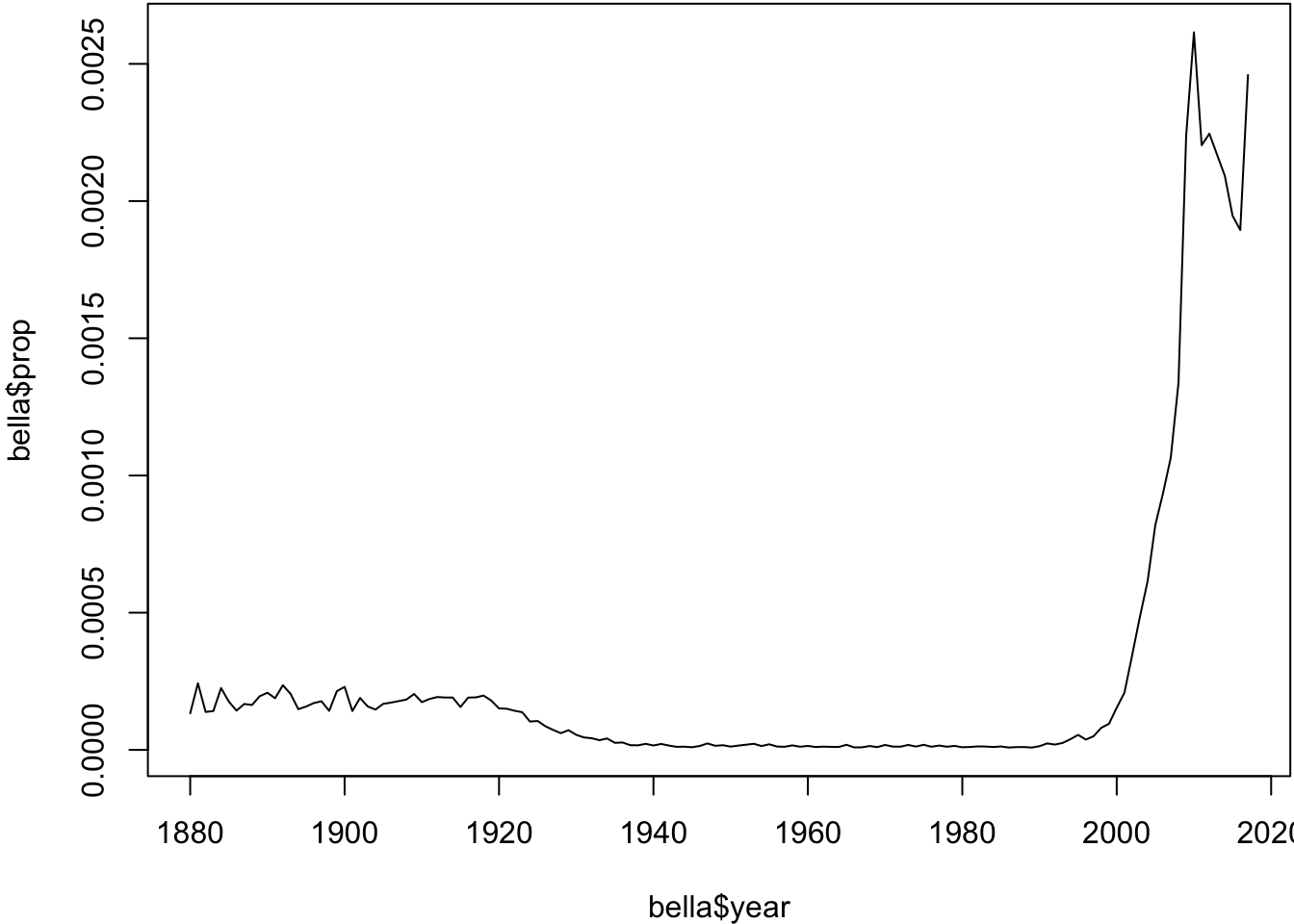
Analyzing the name ‘Bella’
> bella <- babynames %>% filter(sex=="F", name=="Bella")
> plot(bella$year, bella$prop, type="l")